Module 7 Creating project directory templates
Module 6 described the advantages of organizing all the files for a research project within a single directory, and the added advantages of using a consistent directory structure for all of the experiments or projects in your research group. In this module, we’ll walk through the steps required to design and create a template for your project directories. Creating and using a common template for your directory structure for projects will help create consistency across projects in the directory structure, which can facilitate the use and re-use of automated tools like code scripts across different experiments.
Objectives. After this module, the trainee will be able to:
- Be able to designed a structured project directory template for research projects
- Understand how project directories can be turned into RStudio “Projects”
7.1 Goals in designing a project template
Designing a project template will include two parts—first, designing a conceptual template for your file organization and, second, creating a physical implementation of that concept. The conceptual template will develop a structure and rules for how you’ll organize and name files within a project directory. The physical template will use these ideas to develop a file directory that follows that organization, which you can then copy, paste, and adapt each time you start a new project.
In other words, before you open your computer to make a “physical” template, you should design it. This involves deciding what types of data will go into a project directory, how those files will be organized within the directory and the naming conventions for files. In other words, you should create a blueprint for your template before you create a physical template.
The hardest part of this is the conceptual part—deciding on the structure and rules you will consistently use. This is a process of designing, and so you can make this process a bit easier by following principles that facilitate design. For example, as you design, it’s useful to start by defining the problem.165 What are you aiming to achieve with your file organization system?
Based on our own experiences and the advice of others,166 key goals to consider for a research project directory template are that the system:
- Keeps all files for a research project within a single directory, using subdirectories to organize files into a hierarchical structure
- Keeps data collection and analysis separate (see module 1)
- Avoids or removes unnecessary files
- Uses meaningful names for files and subdirectories, allowing easy navigation and discoverability (module 6) by a new user
- Facilitates creation of reports and analysis that incorporate data from different assays for an experiment
- Makes it easy to share all project files across the team, as well as publicly, once a paper is published
- Makes it easy to implement version control for a project (modules 9–11)
- Incorporates enough flexibility to be used with minimal changes across many research projects
7.2 Steps in designing the conceptual blueprint for a project directory template
As you design a conceptual framework for a project directory template, you can break the process into a few key steps:
- Observe your current research project practices
- Determine which subdirectories you’ll include and how you’ll name them
- Decide on file name conventions
In this section, we’ll go into detail about each of these tasks.
7.2.1 Observe your current research project practices
As you work on this blueprint, you will want to prioritize how it will fit the needs of the user—your research group. One way you can do this is to follow a key early step in the design process: observe.167 One of the best ways to get an idea of what your research group needs within a project directory is to take a survey of past research projects from your group. Make a list of what types of data were collected and what types of pre-processing and analysis were done using those data. For each type of data, it’s helpful to make a note its typical file type and typical size. How are data for a specific assay divided across files? Are the data for all animals and all timepoints included in a single spreadsheet file? If so, are they saved in the same sheet, or divided across sheets? Conversely, are different files used for the data from different animals or different time points?
Doing this kind of survey will help you create a standard structure of subdirectories that you can use consistently across the directories for all the projects in your research program. Of course, some projects may not include certain files, and some might have a new or unusual type of file. You can customize the directory structure to some degree for these types of cases, but it is still a big advantage to include as many common elements as possible across all your projects. The best way to determine what these common elements might be in future projects is to look at your past projects.
It can also be helpful to have an example of each file type, to help capture the typical size, structure, and contents of each type of file. For data that you will record yourself in the lab, these can be the templates that you developed to collect the data in a tidy format (modules 3–5). For data from equipment, these can be one or more example files from the equipment that you have collected for a past project. Having these example files will help you to develop a template project report that can input the type of data that you typically collect for this type of project.
This is also a good stage to diagnose if there are data collection files that are not successful in separating data collection from data pre-processing and analysis (module 1). As you progress, you may also want to add templates that serve as a starting point for data collection files within this project. This idea of creating data collection templates is described in detail in modules 4 and 5.
7.2.2 Determine which subdirectories you’ll include and how you’ll name them
Once you have examined past projects to determine the types of files that you’ll normally include in a project, you can decide how to organize them into subdirectories. This subdirectory structure will create the core framework of your project directory template.
In general, as you design the structure of subdirectories, keep in mind that a key aim is to create a structure that is general enough that you can use it consistently for many projects, but also clear enough that you can quickly find things within the directory. As one paper notes, you want a directory setup that is “flexible and configurable.”168
A number of researchers have put a lot of thought into how to organize project directories for scientific research.169 A common theme across these papers is to include subdirectories to store files in four main areas:
- data
- code
- reports
- meta-documentation
We’ll go through each of these to discuss what might be included in each, as well as how it might make sense to name subdirectories in each of the areas.
Data subdirectories
Data should be saved in an area that is separate from any code for analysis. See module 1 for a deeper discussion on the benefits of separating data from analysis to improve reproducibility. The raw data should also be treated as “read-only”—in other words, the raw data should never be edited or changed. To work with the data, including any necessary quality control, pre-processing, or analysis, these raw data should be read into a separate program for analysis. That way, you can work with the data (and even create and save intermediary, “processed” versions of the data), while maintaining the original raw files without alteration.
There are different recommendations on how to name and organize subdirectories for data. Several papers recommend having separate subdirectories for the raw data versus intermediate processed data. Some researchers have suggested naming the subdirectory for raw data as “data-raw” and the one for intermediate data as “data.”170 Others have suggested naming the raw data subdirectory as “data” and the one for intermediate data “outputs.”171 Either or these choices—or a reasonable alternative—is fine, as long as you use your naming scheme consistently every time you set up a project directory. In some cases, you may also decide to use the raw data directory keep the code scripts that you used to create intermediate processed data from those raw data.172
One thing that can be challenging is working with raw data files that are extremely large, as in this case you may not have room on your personal computer to store the full set of raw data. One article suggested a solution: store a smaller example dataset in your project directory that can be used to test or demonstrate the analysis code, while storing the full set of raw data files on a computer with adequate storage capacity.173 The article notes:
“If your data are very large, or streaming, an alternative is to include a small-sample dataset so that people can try out the techniques without having to run very expensive computations.”174
Code subdirectories
Next, you’ll want to include one or more subdirectories for code. Again, this structure helps in separating data collection from data analysis (module 1). This code may include data for cleaning and pre-processing the data, although some researchers choose to put code for these steps in the “raw-data” subdirectory, as separate files from the raw data files but within the same section of the project directory. This code will also include code to analyze and visualize the data. In some cases, it might include code for functions that you plan to reuse within different code scripts in the project or even across projects.
One article recommended having a single code subdirectory, named “code.”175 This subdirectory can store any code scripts (outside of any code running as part of a report RMarkdown file; see modules 18–20). Another recommends that, if you have both compiled code (like C code) and code scripts (for a language like R), you may want to have separate subdirectories for source code (“src”) versus compiled code or scripts (“bin”).176
Other researchers have recommended having an “R” subdirectory that is only used for code that you write for reusable R functions, ones that you plan to use several times across other code scripts in your project.177 For the code that runs data analysis, they recommend a separate subdirectory named “model”178 or “analysis.”179
Report subdirectories
You can leverage the standard structure you’ve created for your directory to create a report. This can be designed to generate some exploratory analysis and visualizations that you find you typically want to generate from your data. You can create this using tools for reproducible reports—in R, a key tool for this is RMarkdown. Here, we’ll cover using this tool for creating a report, and there are many more details in modules 18 through 20. Briefly, RMarkdown allows you to include both code and text meant for humans within a single, plain text document. This document can then be rendered, a process that executes the code and formats the text meant for humans, producing a document in an easy-to-read format like Word or PDF.
Whether you use these tools or not, though, you should have a space in your project directory to keep the documents you create to report your findings. These will include initial reports, but they can also include documents like paper articles, conference abstracts, posters, and presentations.
You could use a single subdirectory for these report files, named something like “doc.”180 Alternatively, if you are using RMarkdown files, you could keep these files (which are the ones you should work on as you edit reports) in one subdirectory and have another subdirectory to store the output of those RMarkdown files (the generated reports in a format like PDF or Word, which you should treat as read-only if they were generated from an RMarkdown file).181 These two subdirectories could be named “analysis” and “output”, respectively.182 Another article recommends using separate subdirectories for different types of report outputs, for example “posters”, “manuscript”, and “slides.”183
Metadata subdirectories or files
The final major area to cover in your project directory are files for metadata. These files contain information that describes your project as a whole. In some cases you might store this information in subdirectories, but in many cases, this information might alternatively go in a single file at the main level of the project directory.
There are a number of pieces of information that you may want to include in this metadata. You could include, for example, information about the experiment, like which model animal you were using or which treatment you were testing. You could also include information related to the code analysis. One piece of information that’s very important, for example, is a list of the dependencies and versions of software. For example, if you used R for analysis, which version of R did you use, and which packages did you use to supplement the base R distribution?
The metadata can also provide some information on who was involved in the project, what role each person had, and the conditions for reusing elements of the project, like code and data. If the project directory will be shared once you complete the information, these details on reuse will be particularly helpful. This might include information, for example, about the license under which you are sharing any code within the project.
Several articles suggest sharing this metadocumentation through a type of file called a “README” file.184 The idea of a README file comes from the tradition of software engineering. The code that builds a software system can be large and complex, with many source files that must be combined and compiled to “build” the software. Since it can be hard to navigate the directory with all these files, one long-standing solution is to include a README file. This README file is put in the top level of the directory’s hierarchy. This way, when someone opens the directory, they’ll see this file right away, and it has a very discoverable filename, since “README” tells you exactly what you should do with it.
This file serves as a spot where you can help someone navigate the rest of the files in the directory. You can also use it to record metadata for the project: things like who was involved in the research and a citation to a resulting paper. You can write this file in plain text, but if you’re sharing the project directory through a version control platform, you might want to explore writing it in the mark-up language Markdown (see module 11 for more on using Markdown for a README file that will be shared through a version control platform).
7.3 Decide on file name conventions
The final step in designing a conceptual framework is to create some rules for how you’ll name files in the project. When you create rules for how you name files, the first thing to keep in mind is this: use names that balance generalizability with discoverability.
In terms of generalizability, you want to use file names that generalize to all of your projects. In other words, don’t make file names so specific that they won’t work the next time you do a project. You may, for example, want to include the name of the grant or experiment in your filename for your metadata. This instinct is good—it can be helpful to include information about your experiment somewhere in the filenames. But try to put this type of information as high in the directory structure as possible: specifically, put that information in the name of the project directory itself. Then, within the filenames in that directory, use names that can be used across many projects.
This is because if a type of file always has the same name in all your project directories, you and your team will find it easy to find that file and use that file as they move from one project to the next. It even will allow you to write code that leverages the fact that certain files always have the same name across projects.
You don’t, however, want to make file names so general that they aren’t discoverable (see module 6 for more on the idea of discoverability). A filename, in other words, shouldn’t be so generic that its name doesn’t give you an good idea of what it contains.
Say, for example, that you used the name “file_a” for the metadata file in your project directory. This filename is generic and would work across many projects, unlike a filename that includes something like the name of the experiment. It’s so generic, though, that it would be hard for someone to figure out what the file contains just by looking at its name. A better name would be something like “experiment_metadata”—generic enough to work across many projects, but detailed enough to be discoverable.
Another thing to consider, as you select file naming conventions, is to avoid special characters in filenames. We discussed this idea in module 4, in the context of avoiding special characters in the column names and cell entries in a data collection spreadsheet. Similar considerations apply to filenames. While many operating systems allow you to include things like spaces in filenames, these special characters can make it harder to write code that works with the file. Try to write filenames that have only alphanumeric characters and underscores.
One of the biggest culprits here are spaces. It is appealing to include spaces in a filename: it’s easier to read the words in the filename if they’re separated by spaces. You should, though, get out of this habit. Once you move to coding with the file, the spaces will be a pain. Often, when a computer parses code, it thinks it’s gotten to the end of something when it gets to a space. When it gets to a space in a filename, for example, it can think it’s gotten to the end of that filename in some contexts. So, if you put a space in the middle of a filename, it can confuse the computer.
There are ways to help the computer out—ways to “escape” special characters, to the computer will treat them literally rather than attributing special meaning to these special characters. However, it’s no fun to have to do over and over again as you use a set of files. It’s much simpler to enforce a rule to use underscores instead of spaces in your filenames: “experiment_metadata.Md”, for example, rather than “experiment metadata.Md”. The underscores serve the same purpose of legibility that the spaces do, by separating words within the filename. They won’t confuse the computer in the same way, though.
Another consideration is that it is good practice to write code using relative pathnames that start from the top-level of the project directory.185 In other words, tell the computer where to find the files starting from the top level of the project directory. This is because these relative pathnames will work equally well on someone else’s computer, whereas if you use file pathnames that are absolute (i.e., giving directions to the file from the root directory on your computer), then when someone else tries on run the code on their own computer, it won’t work and they’ll need to change the filepaths in the code, since everyone’s computer has its files organized differently. For example, if you, on your personal computer, have the project directory stored in your “Documents” folder, while a colleague has stored the project directory in his or her “Desktop” directory, then the absolute filepaths for each file in the directory will be different for each of you. The relative pathnames, starting from the top level of the project directory, will be the same for both of you, though, regardless of where you each stored the project directory on your computer.
When it comes to code scripts in your project, there’s also one other think you may want to consider in naming conventions. Often, you will have divided key tasks (like data entry, pre-processing, and analysis) into separate scripts. The scripts will need to follow a specific order when they are run to recreate the results for the project. In this case, you may want to consider starting each script’s filename with a number, where the numbers indicate the order that the scripts should be run.186 For example, your script files might look like: “01_reading_data.R”, “02_preprocessing_data.R”, “03_exploratory_analysis.R”, and so on.
There are other cases where you’ll have more than one of a certain file type. For example, within your raw data files, you may have one file per sample for an assay like flow cytometry, or one file per timepoint if you’re recording data for multiple timepoints.
In this case, you’ll need to develop rules for how you name these files, chosing a system that allows different filenames for each file. As you do, there are two things you can keep in mind: first, adhering to standards when possible, and second designing filenames in a way that you can leverage something called regular expressions.
In module 2, we talked about standards in terms of recording data. We emphasized how powerful standards can be if they are regularly followed in practice. Just as standards are a powerful tool when recording data, they are also a powerful tool when creating filenames. If there are conventions in your discipline for how certain files are named, follow these.
One example is that there may be a standard way that a piece of laboratory equipment names a file. For example, it may always include some elements like the sample name and the date that the sample was run through the equipment. In this case, you don’t want to change these filenames. You want to keep them in the standard format, as people may have already built tools to work with that standard. If you change from the standard, those tools wouldn’t be available. Standards also tend to help with discoverability, so if you change the filenames for the standard, it may make it harder for someone else to navigate your files.
If standards don’t exist for naming a certain type of file, you can create your own standards. As you do, you can think about how to create filenames that leverage regular expressions. These are coding tools that can search for patterns that you specify in character strings, including filenames.
As an example, say you have files that record separate timepoints of your experiment. You could pick a naming convention that always includes the timepoint in the filename, recorded using the same conventions and always in the same place in the filename. If you collect at timepoints that you call “day 7”, “day 14”, and “day 21”, you might incorporate these within the filenames using “D” for “day” and the two digits for the number. This would result in files that include something like “D07”, “D14”, or “D21” in the name. It would be straightforward to pull this information back out of the filenames if you always put it in the same spot in the filename. For example, if you’re collecting bacterial loads by measuring colony-forming units, you might name the files, “cfu_D07.xlsx”, “cfu_D14.xlsx”, and “cfu_D21.xlsx”. Because you have always put the varying information (the timepoint) in the same spot, it will be easy to extract this with code using regular expressions.
7.4 Creating and using a project template
Once you have a blueprint for a template for a project directory, you can create this as a “physical template” directory on your computer. This process is, once you have designed the template, very easy. It involves no fancy tools—in fact, it’s so straightforward that at first it might seem too simple to be useful. For this basic approach, you will create an example file directory that captures your desired project directory structure. If you have created any templates, either for data collection (module 4 and 5) or for reports (modules 18–20), you can include those within this structure.
In other words, you will create a basic file directory with the desired template files and file directory structure. When you are ready to start a new project, you will copy this template, rename the copy to be specific to the new project, and then use this directory to store and work with the data you collect for the project. Figure 7.1 gives an example of what the final resulting template directory might look like, as well as how it can be copied, renamed, and used as you start new projects.
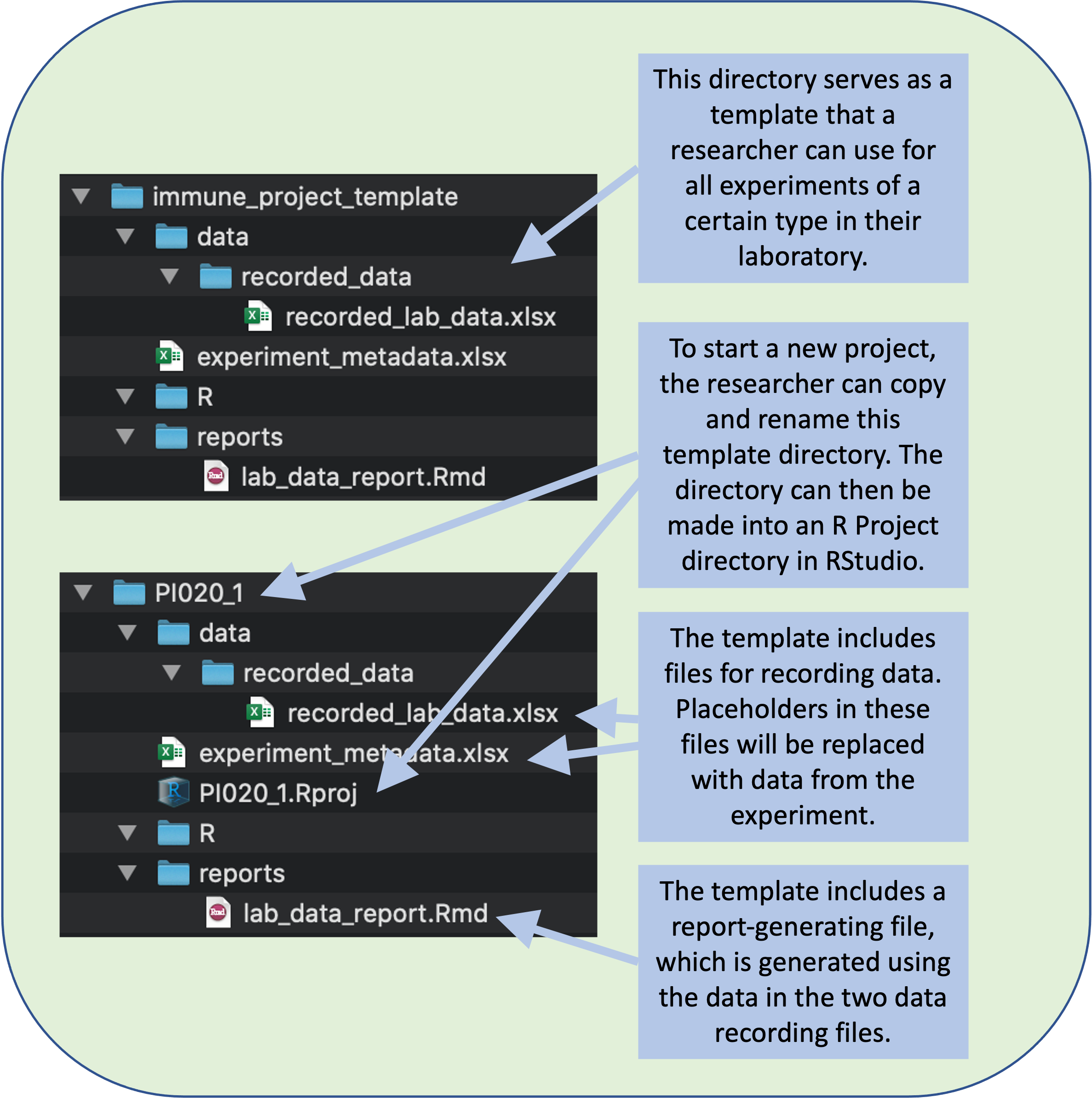
Figure 7.1: A research group can create a file directory that will serve as a template for all the experiments of a certain type in your laboratory. The template can include templates of files for data recording and for generating reports. To start recording data for a new experiment, a researcher can copy and rename this template directory.
This template is not restrictive—it serves as a starting point, but it can be adapted for each specific project. For example, if you are collecting data from an assay that you have not used in past experiments, you can add a new data subdirectory to your project directory to use for storing that new type of data. Figure 7.2 shows an example of how you could customize the basic template shown in Figure 7.1.
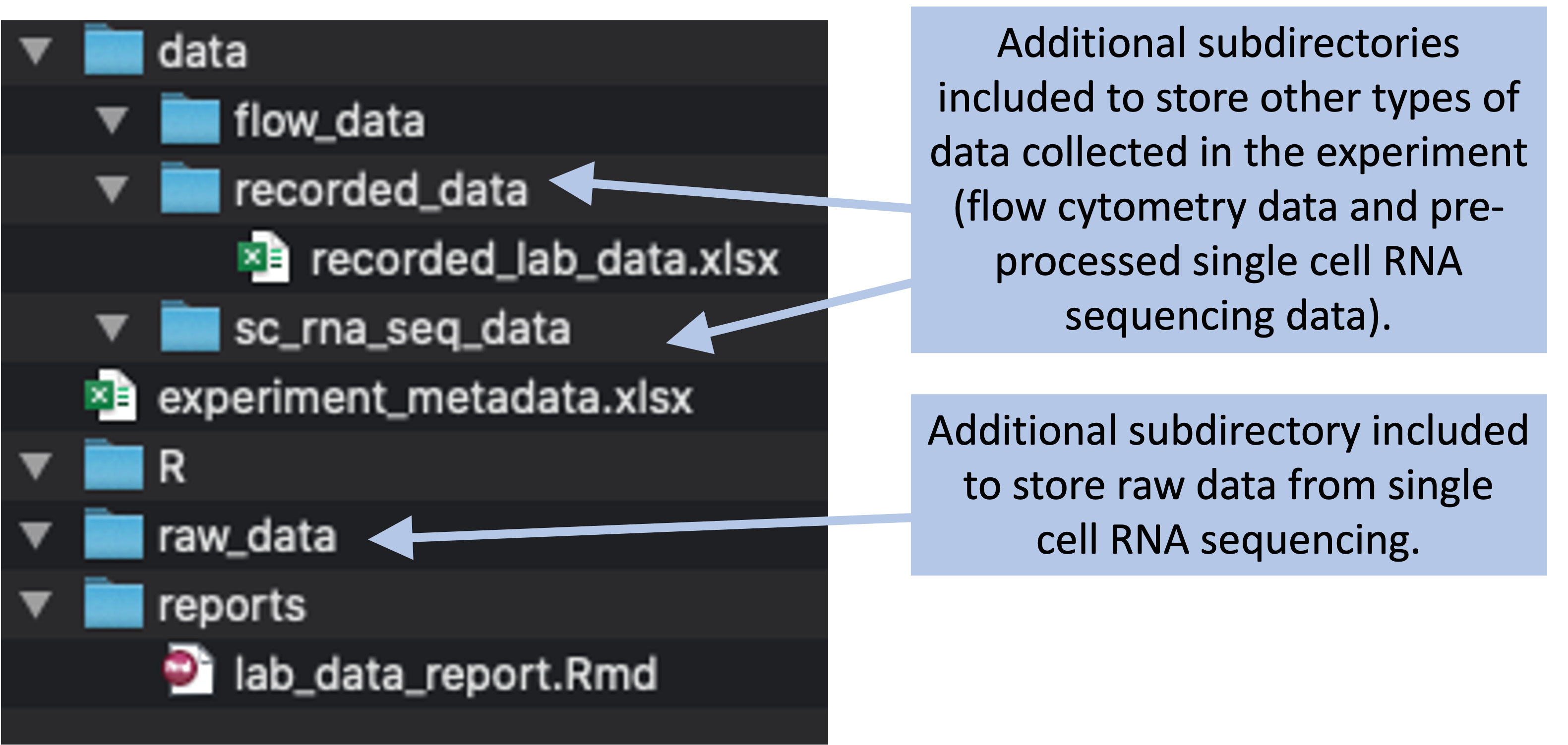
Figure 7.2: Example of a more complex project directory structure that could be created, with directories added to store data collected through flow cytometry and single cell RNA sequencing.
Keep in mind, though, that you do want to keep a balance, where you avoid unneeded changes to the project template within each specific project’s directory. This is because many of the benefits of standardizing (e.g., knowing where things are, building tools that leverage the standardized directory structure) are lost as the directories for specific projects grow to be more and more different from each other.
Figure 7.3 gives a basic walk-through of the simple steps you’ll use to start a new project directory once you’ve created this type of template (we will cover this example in much more detail in module 8, where we walk through a full example of designing and using a project template).
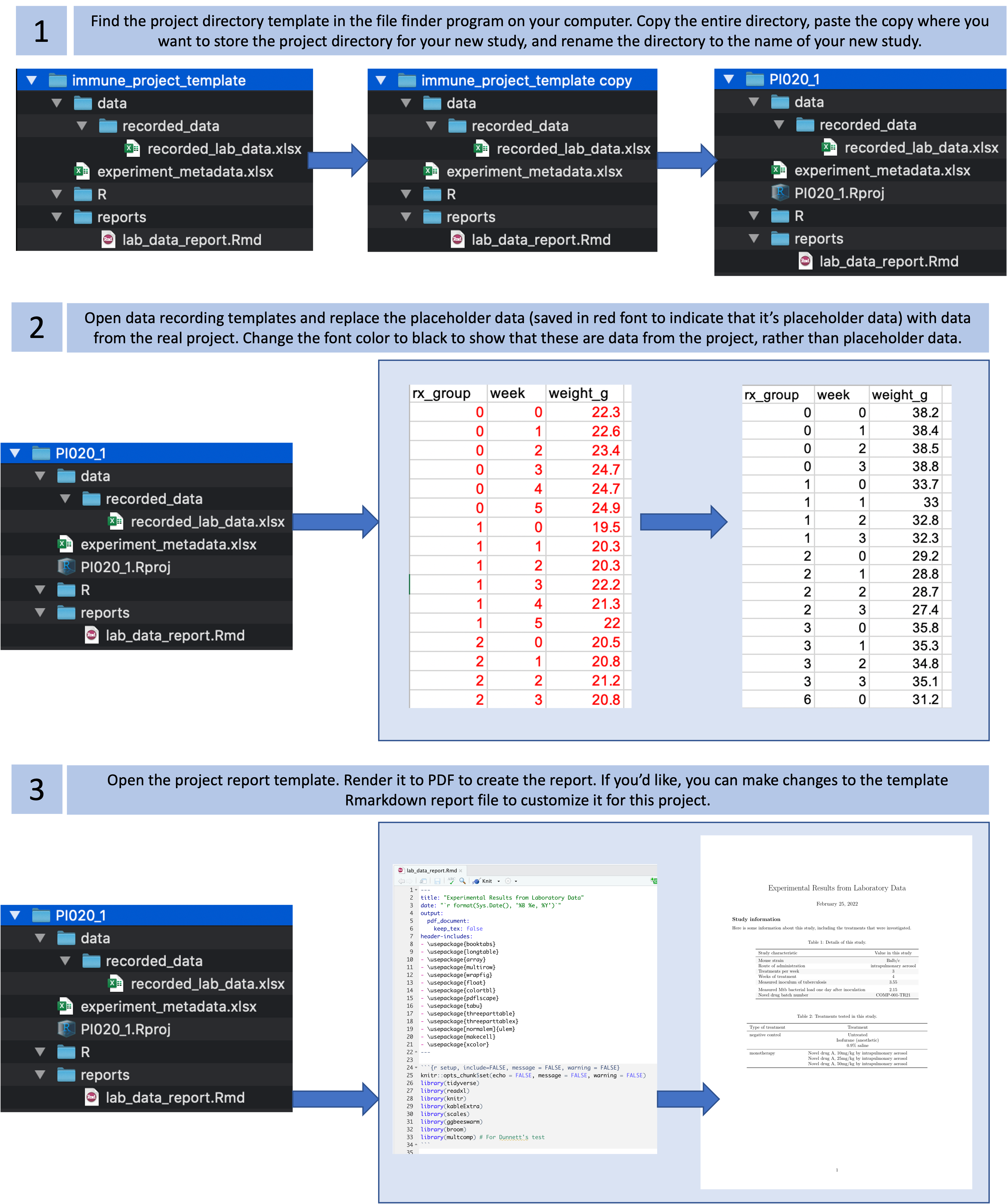
Figure 7.3: Steps in using a basic project directory template that you have created for a type of study or experiment.
7.5 Project directories as RStudio Projects
If you are using the R programming language for data pre-processing, analysis, and visualization—as well as RMarkdown for writing reports and presentations—then you can use RStudio’s “Project” functionality to make it even more convenient to work with files within a research project’s directory. You can make any file directory a “Project” in RStudio by chosing “File” -> “New Project” in RStudio’s menu. This gives you the option to create a project from scratch or to make an existing directory and RStudio Project.
When you make a file directory an RStudio Project, it doesn’t change much in the directory itself except adding a “.RProj” file. This file keeps track of some things about the file directory for RStudio, including preferred settings for RStudio to use when working in that project.
When you are working in an RStudio Project, RStudio will automatically move your working directory to be the top-level directory of the Project directory. This makes it easy to write code that uses this directory as the presumed working directory, using relative file paths to identify and files within the directory. We discussed the value of using relative pathnames earlier in this module, when we discussed how to design file naming conventions for your project directory. In particular, if you share the project directory with someone else, they can similarly open the RStudio Project in their own version of RStudio, and all the relative pathnames to files should work on their system without any problems. This feature helps make code in an RStudio Project directory reproducible across different people’s computers.
There are some other advantages, as well, to turning each of your research project directories into RStudio Projects. One is that it is very easy to connect each of these Projects with GitHub, which facilitates collaborative work on the project across multiple team members while tracking all changes under version control. If you are tracking the project directory under the Git version control system, then when you open the RStudio Project, there will be a special tab in one of the panes to help in using Git with the project. This tab provides a visual interface for you to commit changes you’ve made, so they are tracked and can be reversed if needed, and also so you can easily push and pull these committed changes to and from a remote repository, like a GitHub repository, if you are collaborating with others. This functionality is described in modules 9 through 11.
Having your project directories set up as R Projects also makes it easy to navigate among different projects. When you close RStudio and reopen it, it will automatically open in the last Project you had open. There is a small tab in the top right hand corner of the RStudio window that lists the project you are currently in. To move to a different Project, you can click on the down arrow beside this project name. There will be a list of your most recent projects, as well as options to open any Project on your computer. If you want to work in RStudio, but not in any of the Projects, you can choose to “Close Project”.