Chapter 4 Generalized linear models
4.1 Readings
The readings for this chapter are:
- Bhaskaran et al. (2013) Provides an overview of time series regression in environmental epidemiology.
- Vicedo-Cabrera, Sera, and Gasparrini (2019) Provides a tutorial of all the steps for a projecting of health impacts of temperature extremes under climate change. One of the steps is to fit the exposure-response association using present-day data (the section on “Estimation of Exposure-Response Associations” in the paper). In this chapter, we will go into details on that step, and that section of the paper is the only required reading for this chapter. Later in the class, we’ll look at other steps covered in this paper. Supplemental material for this paper is available to download by clicking http://links.lww.com/EDE/B504. You will need the data in this supplement for the exercises for class.
- B. G. Armstrong, Gasparrini, and Tobias (2014) This paper describes different data structures for case-crossover data, as well as how conditional Poisson regression can be used in some cases to fit a statistical model to these data. Supplemental material for this paper is available at https://bmcmedresmethodol.biomedcentral.com/articles/10.1186/1471-2288-14-122#Sec13.
The following are supplemental readings (i.e., not required, but may be of interest) associated with the material in this chapter:
- B. Armstrong (2006) Covers similar material as Bhaskaran et al. (2013), but with more focus on the statistical modeling framework (highly recommended!)
- Gasparrini and Armstrong (2010) Describes some of the advances made to time series study designs and statistical analysis, specifically in the context of temperature
- Basu, Dominici, and Samet (2005) Compares time series and case-crossover study designs in the context of exploring temperature and health. Includes a nice illustration of different referent periods, including time-stratified.
- Imai et al. (2015) Typically, the time series study design covered in this chapter is used to study non-communicable health outcomes. This paper discusses opportunities and limitations in applying a similar framework for infectious disease.
- Lu and Zeger (2007) Heavier on statistics. This paper shows how, under conditions often common for environmental epidemiology studies, case-crossover and time series methods are equivalent.
- Gasparrini (2014) Heavier on statistics. This provides the statistical framework for the distributed lag model for environmental epidemiology time series studies.
- Dunn and Smyth (2018) Introduction to statistical models, moving into regression models and generalized linear models. Chapter in a book that is available online through the CSU library.
- James et al. (2013) General overview of linear regression, with an R coding “lab” at the end to provide coding examples. Covers model fit, continuous, binary, and categorical covariates, and interaction terms. Chapter in a book that is available online through the CSU library.
4.2 Splines in GLMs
We saw from the last model, with a linear term for mean daily temperature, that the suggested effect on mortality is a decrease in daily mortality counts with increasing temperature. However, as you’ve probably guessed that’s likely not entirely accurate. A linear term for the effect of exposure restricts us to an effect that can be fitted with a straight line (either a null effect or a monotonically increasing or decreasing effect with increasing exposure).
This clearly is problematic in some cases. One example is when exploring the association between temperature and health risk. Based on human physiology, we would expect many health risks to be elevated at temperature extremes, whether those are extreme cold or extreme heat. A linear term would be inadequate to describe this kind of U-shaped association. Other effects might have a threshold—for example, heat stroke might have a very low risk at most temperatures, only increasing with temperature above a certain threshold.
We can capture non-linear patterns in effects, by using different functions of X. Examples are \(\sqrt{X}\), \(X^{2}\), or more complex smoothing functions, such as polynomials or splines. Polynomials might at first make a lot of sense, especially since you’ve likely come across polynomial terms in mathematics classes since grade school. However, it turns out that they have some undesirable properties. A key one is that they can have extreme behavior, particularly when using a high-order polynomial, and particularly outside the range of data that are available to fit the model.
An alternative that is generally preferred for environmental epidemiology studies is the regression spline. The word “spline” originally comes from drafting and engineering (ship building, in particular), where it described a flexible piece of wood or metal that you could use to draw a curved line—it created a curve that was flexible enough—but just flexible enough—to fit a space (see Wikipedia’s very interesting article on flat splines for more).
Splines follow a similar idea in mathematics, making them helpful tools when a line won’t fit your data well. In general, a spline fits together a few simpler functions to create something with a curve or non-linearity. Each simpler function operates within an interval of the data, and then they join together at “knots” along the range of the data. Regression splines are therefore simple parametric smoothing function, which fit separate polynomial in each interval of the range of the predictor; these can be linear, quadratic, and cubic.
The simplest example is a linear spline (also called a piecewise linear function). This type of spline creates non-linearity by having a breakpoint at the knot, allowing the slope of the line to be different in the intervals of data on either side of the knot. The following plot shows an example. Say you want to explore how mean temperature varies by the day in the year (Jan 1 = 1, Jan 2 = 2, and so on) in the London example dataset from the last chapter. Temperature tends to increase with day of year for a while, but then it changes around the start of August, after that decreasing with day of year. This patterns means that a line will give a bad fit for how temperature changes with day of year, since it smooths right through that change. On the other hand, you can get a very reasonable fit using a linear spline with a knot around August 1 (day 213 in the year). These two examples are shown in the following plot, with the linear function fit on the left and the linear spline on the right:
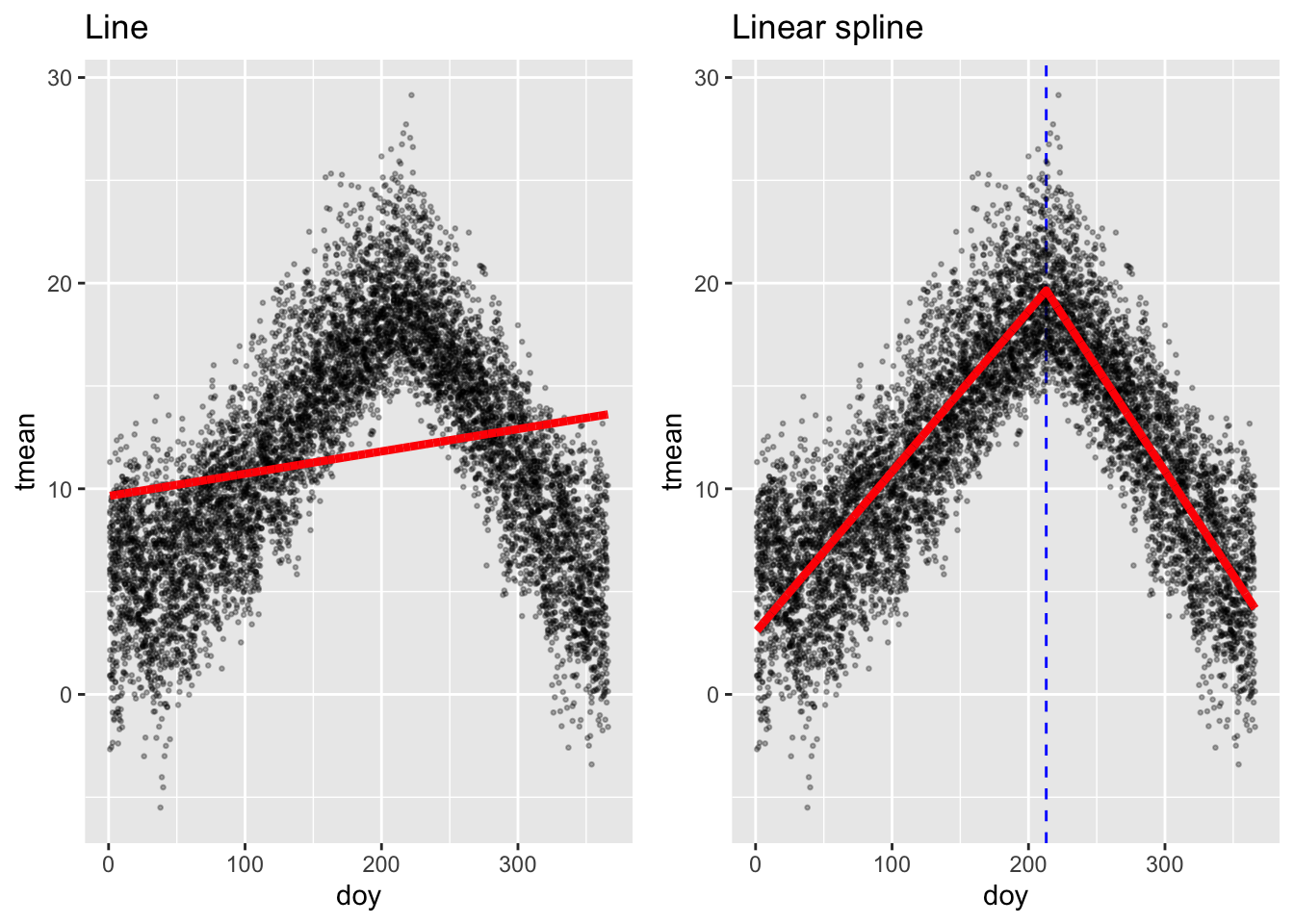
If you were to write out these regression models in mathematical notation, the linear one is very simple:
\[ Y_t = \alpha + \beta X_t \] where \(Y_t\) is the temperature on day \(t\), \(\alpha\) is the model intercept, \(X_t\) is the day of the year on day \(t\), and \(\beta\) is the estimated coefficient for \(X_t\).
The notation for the model with the linear spline is a bit more complex:
\[ Y_t = \alpha + \beta_1 X_t + \beta_2 (X_t - k)_+ \]
Here, \(Y_t\) is again the temperature on day \(t\), \(X_t\) is again the day of the year on day \(t\), and \(\alpha\) is again the intercept. The term \(k\) is the “knot”—the value of \(X\) where we’re letting the slope change. In this example, we’re using \(k = 213\). The term \((X_t - k)_+\) has a special meaning—it takes the value 0 if \(X_t\) is in the interval to the left of the knot, while if \(X_t\) is in the interval to the right of the knot, it takes the value of \(X_t\) minus the knot value:
\[ (X_t - k)_+ = \begin{cases} 0, & \mbox{if } X_t < k \\ X_t - k, & \mbox{if } X_t \ge k \end{cases} \]
In this model, the coefficient \(\beta_1\) estimates the slope of the line to the left of the knot, while \(\beta_2\) estimates how that slope will change to the right of the knot.
Fortunately, we usually won’t have to get this complex in the model notation, especially when we use more complex splines (where the notation would get even more complex). Instead, we’ll often write out the regression equation in a simpler way, just indicating that we’re using a function of the covariate, rather than the covariate directly:
\[ Y_t = \alpha + f(X_t | \mathbf{\beta}) \]
where we can note that \(f(X_t)\) is a function of day of the year (\(X_t\)), fit in this case using a linear spline, and with a set of estimated coefficients \(\mathbf{\beta}\) for that function (see B. Armstrong (2006) for an example of using this model notation).
While a linear spline is the simplest conceptually (and mathematically), it often isn’t very satisfying, because it fits a function with a sharp breakpoint, which often isn’t realistic. For example, the linear spline fit above suggests that the relationship between day of the year and temperature changes abruptly and dramatically on August 1 of the year. In reality, we know that this change in the relationship between day of year and temperature is probably a lot smoother.
To fit smoother shapes, we can move to higher level splines. Cubic splines (“cubic” because they include terms of the covariate up to the third power) are very popular. An example of a cubic spline function is \(X+X^{2}+X^{3}+I((X>X_{0})*(X-X_{0})^3)\). This particular function is a cubic spline with four degrees of freedom (\(df=4\)) and one knot (\(X_{0}\)). A special type of cubic spline called a natural cubic spline is particularly popular. Unlike a polynomial function, a natural cubic spline “behaves” better outside the range of the data used to fit the model—they are constrained to continue on a linear trajectory once they pass beyond the range of the data.
Regression splines can be fit in a GLM via the package splines. Two commonly
used examples of regression splines are b-splines and natural cubic
splines. Vicedo-Cabrera, Sera, and Gasparrini (2019) uses natural cubic splines, which can be fit with the
ns (for “natural spline”) function from the splines package.
While splines are great for fitting non-linear relationships, they do create some challenges in interpreting the results. When you fit a linear relationship for a covariate, you will get a single estimate that helps describe the fitted relationship between that covariate and the outcome variable. However, when you use a non-linear function, you’ll end up with a mix of coefficients associated with that function. Sometimes, you will use splines to control for a potential confounder (as we will in the exercises for this first part of the chapter). In this case, you don’t need to worry about interpreting the estimated coefficients—you’re just trying to control for the variable, rather than inferring anything about how it’s associated with the outcome. In later parts of this chapter, we’ll talk about how to interpret these coefficients if you’re using a spline for the exposure that you’re interested in, when we talk more broadly about basis functions.
Applied: Including a spline in a GLM
For this exercise, you will continue to build up the model that you began in the examples in the previous chapter. The example uses the data provided with one of this chapter’s readings, Vicedo-Cabrera, Sera, and Gasparrini (2019).
- Start by fitting a somewhat simple model—how are daily mortality counts associated with (a) a linear and (b) a non-linear function of time? Is a linear term appropriate to describe this association? What types of patterns are captured by a non-linear function that are missed by a linear function?
- In the last chapter, the final version of the model used a GLM with an overdispersed Poisson distribution, including control for day of week. Start from this model and add control for long-term and seasonal trends over the study period.
- Refine your model to fit for a non-linear, rather than linear, function of temperature in the model. Does a non-linear term seem to be more appropriate than a linear term?
Applied exercise: Example code
- Start by fitting a somewhat simple model—how are daily mortality counts associated with (a) a linear and (b) a non-linear function of time?
It is helpful to start by loading the R packages you are likely to need, as well as the example dataset. You may also need to re-load the example data and perform the steps taken to clean it in the last chapter:
# Load some packages that will likely be useful
library(tidyverse)
library(viridis)
library(lubridate)
library(broom)
# Load and clean the data
obs <- read_csv("data/lndn_obs.csv") %>%
mutate(dow = wday(date, label = TRUE))For this first question, the aim is to model the association between time and daily mortality counts within the example data. This approach is often used to explore and, if needed, adjust for temporal factors in the data.
There are a number of factors that can act over time to create patterns in both environmental exposures and health outcomes. For example, there may be changes in air pollution exposures over the years of a study because of changes in regulations or growth or decline of factories and automobile traffic in an area. Changes in health care and in population demographics can cause patterns in health outcomes over the study period. At a shorter, seasonal term, there are also factors that could influence both exposures and outcomes, including seasonal changes in climate, seasonal changes in emissions, and seasonal patterns in health outcomes.
It can be difficult to pinpoint and measure these temporal factors, and so instead a common practice is to include model control based on the time in the study. This can be measured, for example, as the day since the start of the study period.
You can easily add a column for day in study for a dataset that
includes date. R saves dates in a special format, which we’re using the in
obs dataset:
## [1] "Date"However, this is just a fancy overlay on a value that’s ultimately saved as
a number. Like most Unix programs, the date is saved as the number of days
since the Unix “epoch”, January 1, 1970. You can take advantage of this
convention—if you use as.numeric around a date in R, it will give you a
number that gets one unit higher for every new date. Here’s the example for
the first date in our example data:
## [1] "1990-01-01"## [1] 7305And here’s the example for the next date:
## [1] "1990-01-02"## [1] 7306You can use this convention to add a column that gives days since the first
study date. While you could also use the 1:n() call to get a number for
each row that goes from 1 to the number of rows, that approach would not
catch any “skips” in dates in the data (e.g., missing dates if only warm-season
data are included). The use of the dates is more robust:
## # A tibble: 8,279 × 2
## date time
## <date> <dbl>
## 1 1990-01-01 0
## 2 1990-01-02 1
## 3 1990-01-03 2
## 4 1990-01-04 3
## 5 1990-01-05 4
## 6 1990-01-06 5
## 7 1990-01-07 6
## 8 1990-01-08 7
## 9 1990-01-09 8
## 10 1990-01-10 9
## # ℹ 8,269 more rowsAs a next step, it is always useful to use exploratory data analysis to look at the patterns that might exist for an association, before you start designing and fitting the regression model.

There are clear patterns between time and daily mortality counts in these data. First, there is a clear long-term pattern, with mortality rates declining on average over time. Second, there are clear seasonal patterns, with higher mortality generally in the winter and lower rates in the summer.
To model this, we can start with fitting a linear term. In the last chapter,
we determined that the mortality outcome data can be fit using a GLM with a
Poisson family, allowing for overdispersion as it is common in real-life
count data like these. To include time as a linear term, we can just include
that column name to the right of the ~ in the model formula:
You can use the augment function from the broom package to pull out the
fitted estimate for each of the original observations and plot that, along
with the observed data, to get an idea of what this model has captured:
mod_time %>%
augment() %>%
ggplot(aes(x = time)) +
geom_point(aes(y = all), alpha = 0.4, size = 0.5) +
geom_line(aes(y = exp(.fitted)), color = "red") +
labs(x = "Date in study", y = "Expected mortality count") 
This linear trend captures the long-term trend in mortality rates fairly well in this case. This won’t always be the case, as there may be some health outcomes—or some study populations—where the long-term pattern over the study period might be less linear than in this example. Further, the linear term is completely unsuccessful in capturing the shorter-term trends in mortality rate. These oscillate, and so would be impossible to capture over multiple years with a linear trend.
Instead, it’s helpful to use a non-linear term for time in the model. We can
use a natural cubic spline for this, using the ns function from the splines
package. You will need to clarify how flexible the spline function should be,
and this can be specified through the degrees of freedom for the spline. A
spline with more degrees of freedom will be “wigglier” over a given data range
compared to a spline with fewer degrees of freedom. Let’s start by using
158 degrees of freedom, which translates to about 7 degrees of freedom per year:
library(splines)
mod_time_nonlin <- glm(all ~ ns(time, df = 158),
data = obs, family = "quasipoisson")You can visualize the model results in a similar way to how we visualized the
last model. However, there is one extra step. The augment function only
carries through columns in the original data (obs) that were directly used
in fitting the model. Now that we’re using a transformation of the time
column, by wrapping it in ns, the time column is no longer included in the
augment output. However, we can easily add it back in using mutate,
pulling it from the original obs dataset, and then proceed as before.
mod_time_nonlin %>%
augment() %>%
mutate(time = obs$time) %>%
ggplot(aes(x = time)) +
geom_point(aes(y = all), alpha = 0.4, size = 0.5) +
geom_line(aes(y = exp(.fitted)), color = "red") +
labs(x = "Date in study", y = "Expected mortality count") 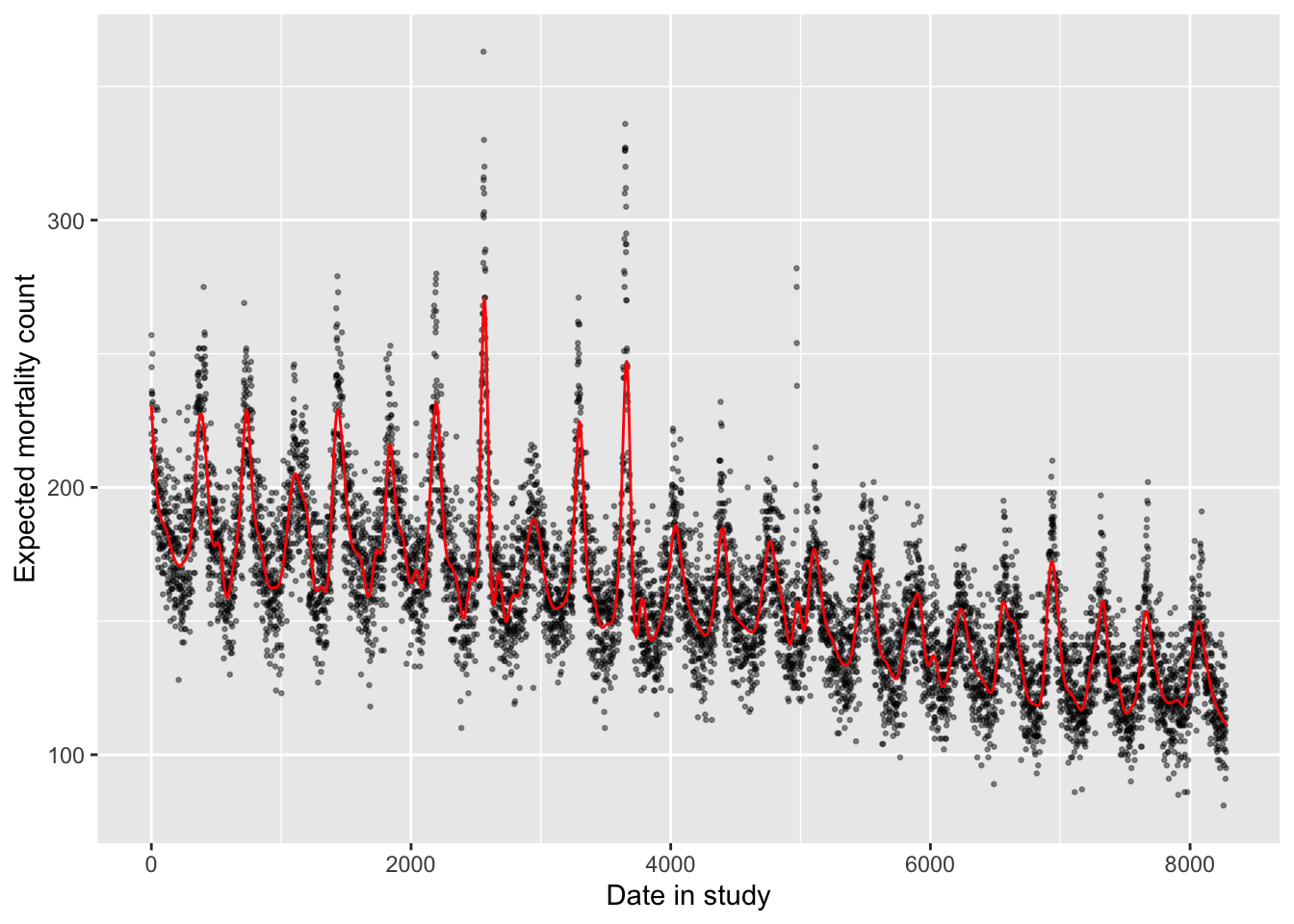
The non-linear term for time has allowed enough flexibility that the model now captures both long-term and seasonal trends in the data.
You might wonder how many degrees of freedom you should use for this time spline. In practice, researchers often using about 6–8 degrees of freedom per year of the study, in the case of year-round data. You can explore how changing the degrees of freedom changes the way the model fits to the observed data. As you use more degrees of freedom, the line will capture very short-term effects, and may start to interfere with the shorter-term associations between environmental exposures and health risk that you are trying to capture. Even in the example model we just fit, for example, it looks like the control for time may be capturing some patterns that were likely caused by heatwaves (the rare summer peaks, including one from the 1995 heatwave). Conversely, if too few degrees of freedom are used, the model will shift to look much more like the linear model, with inadequate control for seasonal patterns.
# A model with many less d.f. for the time spline
mod_time_nonlin_lowdf <- glm(all ~ ns(time, df = 10),
data = obs, family = "quasipoisson")
mod_time_nonlin_lowdf %>%
augment() %>%
mutate(time = obs$time) %>%
ggplot(aes(x = time)) +
geom_point(aes(y = all), alpha = 0.4, size = 0.5) +
geom_line(aes(y = exp(.fitted)), color = "red") +
labs(x = "Date in study", y = "Expected mortality count") 
# A model with many more d.f. for the time spline
# (Takes a little while to run)
mod_time_nonlin_highdf <- glm(all ~ ns(time, df = 400),
data = obs, family = "quasipoisson")
mod_time_nonlin_highdf %>%
augment() %>%
mutate(time = obs$time) %>%
ggplot(aes(x = time)) +
geom_point(aes(y = all), alpha = 0.4, size = 0.5) +
geom_line(aes(y = exp(.fitted)), color = "red") +
labs(x = "Date in study", y = "Expected mortality count") 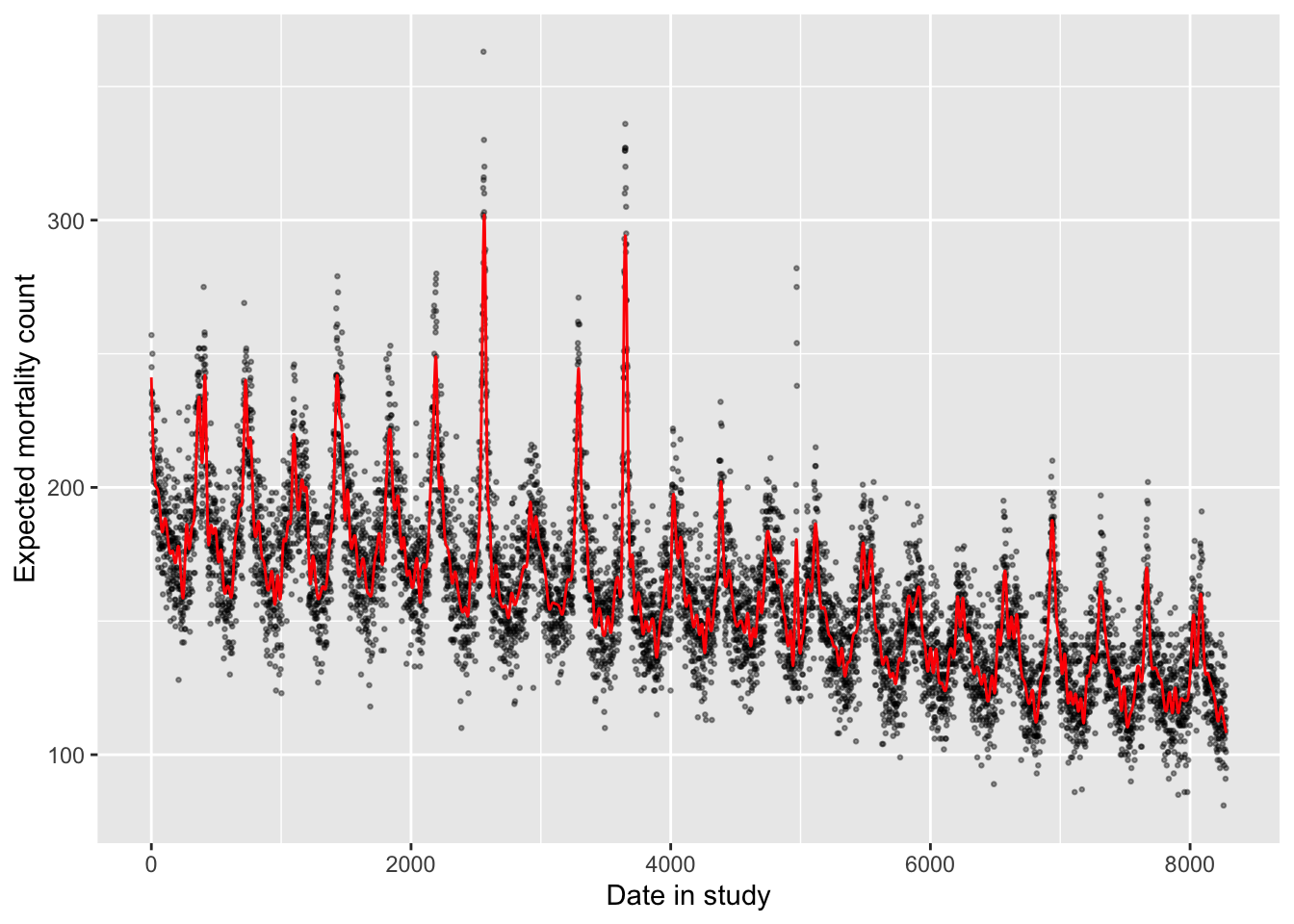
In all cases, when you fit a non-linear function of an explanatory variable, it will make the model summary results look much more complicated, e.g.:
## # A tibble: 11 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 5.26 0.00948 555. 0
## 2 ns(time, df = 10)1 -0.0260 0.0119 -2.18 2.93e- 2
## 3 ns(time, df = 10)2 -0.0860 0.0155 -5.56 2.85e- 8
## 4 ns(time, df = 10)3 -0.114 0.0139 -8.15 4.01e- 16
## 5 ns(time, df = 10)4 -0.196 0.0151 -13.0 4.47e- 38
## 6 ns(time, df = 10)5 -0.187 0.0148 -12.6 2.80e- 36
## 7 ns(time, df = 10)6 -0.315 0.0154 -20.5 5.62e- 91
## 8 ns(time, df = 10)7 -0.337 0.0154 -21.9 1.95e-103
## 9 ns(time, df = 10)8 -0.358 0.0135 -26.5 1.56e-148
## 10 ns(time, df = 10)9 -0.467 0.0244 -19.2 4.49e- 80
## 11 ns(time, df = 10)10 -0.392 0.0126 -31.2 8.01e-202You can see that there are multiple model coefficients for the variable fit
using a spline function, the same as the number of degrees of freedom. These
model coefficients are very hard to interpret on their own. When we are using
the spline to control for a factor that might serve as a confounder of the
association of interest, we typically won’t need to try to interpret these
model coefficients—instead, we are interested in accounting for how this
factor explains variability in the outcome, without needing to quantify the
association as a key result. However, there are also cases where we want to
use a spline to fit the association with the exposure that we are interested
in. In this case, we will want to be able to interpret model coefficients from
the spline. Later in this chapter, we will introduce the dlnm package, which
includes functions to both fit and interpret natural cubic splines within
GLMs for environmental epidemiology.
- Start from the last model created in the last chapter and add control for long-term and seasonal trends over the study period.
The last model fit in the last chapter was the following, which fits for the association between a linear term of temperature and mortality risk, with control for day of week:
mod_ctrl_dow <- glm(all ~ tmean + factor(dow, ordered = FALSE),
data = obs, family = "quasipoisson")To add control for long-term and seasonal trends, you can take the natural cubic
spline function of temperature that you just fit and include it among the
explanatory / independent variables from the model in the last chapter. If you
want to control for only long-term trends, a linear term of the time column
could work, as we discovered in the first part of this chapter’s exercise.
However, seasonal trends could certainly confound the association of interest.
Mortality rates have a clear seasonal pattern, and temperature does as well,
and these patterns create the potential for confounding when we look at how
temperature and mortality risk are associated, beyond any seasonally-driven
pathways.
mod_ctrl_dow_time <- glm(all ~ tmean + factor(dow, ordered = FALSE) +
ns(time, df = 158),
data = obs, family = "quasipoisson")You can see the influence of this seasonal confounding if you look at the model
results. When we look at the results from the model that did not control for
long-term and seasonal trends, we get an estimate that mortality rates tend to
be lower on days with higher temperature, with a negative term for tmean:
## # A tibble: 1 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 tmean -0.0148 0.000354 -41.7 0Conversely, when we include control for long-term and seasonal trends, the estimated association between mortality rates and temperature is reversed, estimating increased mortality rates on days with higher temperature, controlling for long-term and seasonal trends:
## # A tibble: 1 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 tmean 0.00370 0.000395 9.36 1.02e-20- Refine your model to fit for a non-linear, rather than linear, function of temperature in the model.
You can use a spline in the same way to fit a non-linear function for the
exposure of interest in the model (temperature). We’ll start there. However,
as mentioned earlier, it’s a bit tricky to interpret the coefficients from the
fit model—you no longer generate a single coefficient for the exposure of
interest, but instead several related to the spline. Therefore, once we show
how to fit using ns directly, we’ll show how you can do the same thing using
specialized functions in the dlnm package. This package includes a lot of
nice functions for not only fitting an association using a non-linear term,
but also for interpreting the results after the model is fit.
First, here is code that can be used to fit the model using ns directly,
similarly to the approach we used to control for temporal patterns with a
flexible function:
mod_ctrl_nl_temp <- glm(all ~ ns(tmean, 4) + factor(dow, ordered = FALSE) +
ns(time, df = 158),
data = obs, family = "quasipoisson")We can plot the predicted values from this fitted model (red points in the plot below)
compared to the observed data (black dots) using our usual method of using augment to
extract the predicted values:
mod_ctrl_nl_temp %>%
augment() %>%
mutate(tmean = obs$tmean) %>%
ggplot(aes(x = tmean)) +
geom_point(aes(y = all), alpha = 0.4, size = 0.5) +
geom_point(aes(y = exp(.fitted)), color = "red", size = 0.4) +
labs(x = "Daily mean temperature", y = "Expected mortality count") 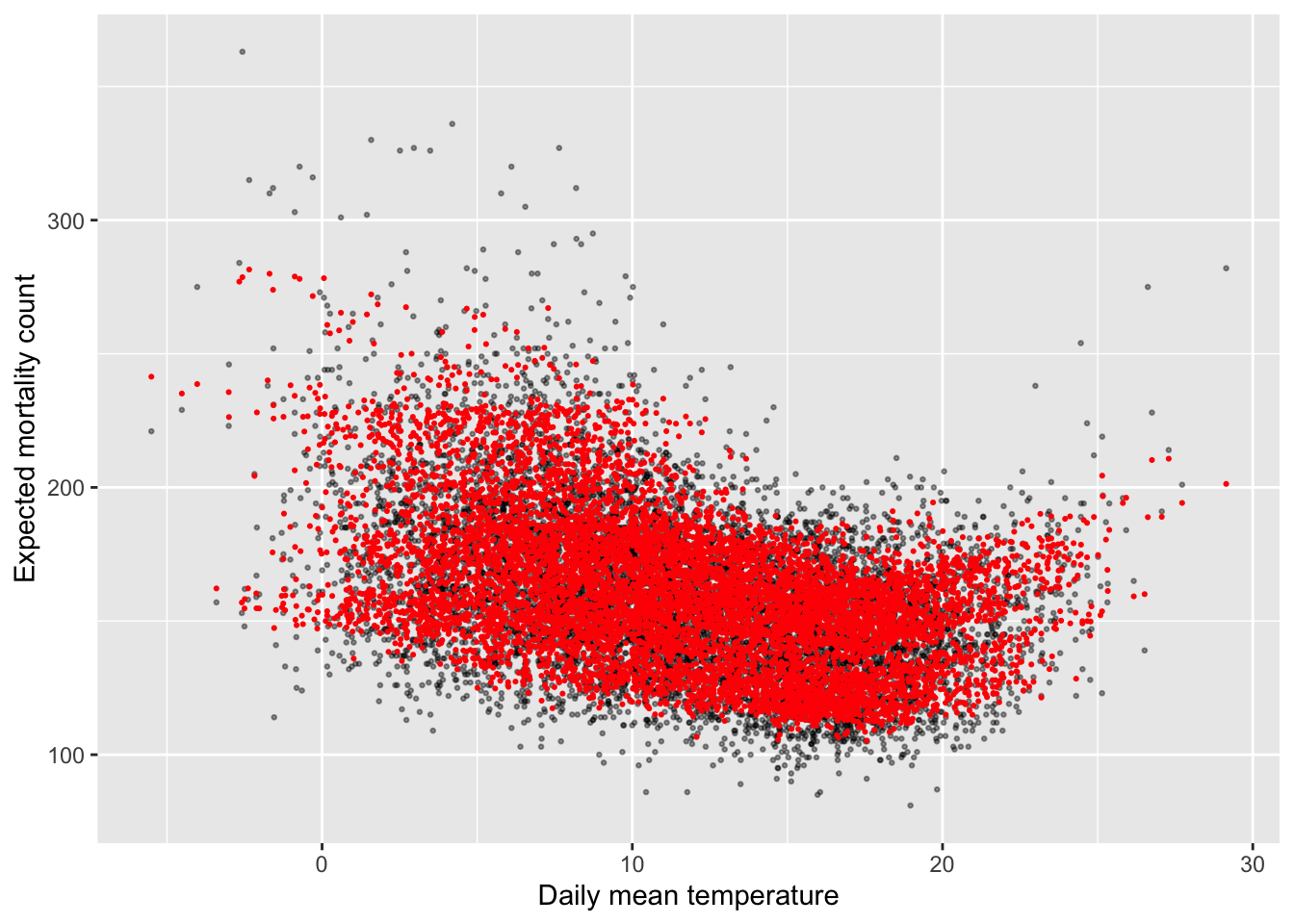
However, these predictions are very variable at any given temperature. This reflects how other independent variables, like long-term and seasonal trends, explain variability in mortality. This makes sense, but it makes it a bit hard to investigate the role of temperature specifically. Let’s look, then, at some other options for viewing the results that will help us focus on the association of the exposure we care about (temperature) with the outcome.
The next part has a lot of steps, so it might at first seem confusing. However, fortunately we won’t always have to do all the steps ourselves—there is a nice R package that will help us. We’ll look at the process first, though, and then the easier way to use a package to help with some of the steps. Also, this process gives us a first look at how the idea of basis functions work. We’ll later expand on these to look at non-linear relationships with the exposure at different lag times, using cross-basis functions, so this forms a starting point for moving into the idea of a cross-basis.
First, we need to think about how temperature gets included in the regression model—specifically, as a function of basis variables rather than as a single variable. In other words, to include temperature as a nonlinear function, we’re going to create a structure in the regression equation that includes the variable of temperature in several different terms, in different transformations in each term. I simple example of this is a second-degree polynomial. If we wanted to include a second-order polynomial function of temperature in the regression, then we’d use the following basis:
\[ \beta_1 T + \beta_2 T^2 \]
Notice that here we’re using the same independent variable (\(T\), which stands for daily temperature), but we’re including both untransformed \(T\) and also \(T\) squared. This function of \(T\) might go into the regression equation as something like:
\[ E(Y) = \alpha + \beta_1 T + \beta_2 T^2 + ns(time) + \mathbf{\gamma^{'}D} \] where \(\alpha\) is the intercept, \(ns(time)\) is a natural cubic spline that controls for time (long-term and seasonal trends) and \(\mathbf{D}\) is day of week, with \(\mathbf{\gamma}\) as the set of coefficients associated with day of week. (Here, I’ve included the outcome, \(Y\), untransformed, as you would for a linear regression, but of course the same idea works with Poisson regression, when you’d instead have \(log(E(Y))\) on the left of the equation.)
When you fit a regression model in a program like R, it sets up the observed data into
something called a model matrix, where it has the values for each observation for each of
the independent variables you want to include, plus a column of “1”s for the intercept, if you
model structure includes one. The regression model will fit a coefficient
for each of these columns in the model matrix. In a simple case, this model matrix will just
repeat each of your independent variables. For example, the model matrix for the model
mod_overdisp_reg, which we fit in the last chapter and which included only an intercept
and a linear term for tmean, looks like this (the model.matrix function will give you
the model matrix of any glm object that you get by running the glm function in R):
## (Intercept) tmean
## 1 1 3.913589
## 2 1 5.547919
## 3 1 4.385564
## 4 1 5.431046
## 5 1 6.867855
## 6 1 9.232628We already start using the idea of basis variables when we include categorical variables, like
day of week. Here is the model matrix for the mod_ctrl_dow model that we fit in the last
chapter:
## (Intercept) tmean factor(dow, ordered = FALSE)Mon
## 1 1 3.913589 1
## 2 1 5.547919 0
## 3 1 4.385564 0
## 4 1 5.431046 0
## 5 1 6.867855 0
## 6 1 9.232628 0
## factor(dow, ordered = FALSE)Tue factor(dow, ordered = FALSE)Wed
## 1 0 0
## 2 1 0
## 3 0 1
## 4 0 0
## 5 0 0
## 6 0 0
## factor(dow, ordered = FALSE)Thu factor(dow, ordered = FALSE)Fri
## 1 0 0
## 2 0 0
## 3 0 0
## 4 1 0
## 5 0 1
## 6 0 0
## factor(dow, ordered = FALSE)Sat
## 1 0
## 2 0
## 3 0
## 4 0
## 5 0
## 6 1You can see that the regression call broke the day-of-week variable up into a set of indicator variables, which equal either 1 or 0. There will be one less of these than the number of categories for the variable; in otherwords, if the categorical variable took two values (Weekend / Weekday), then this would be covered by a single column; since there are seven days in the week, the day-of-week variable breaks into six (7 - 1) columns. The first level of the categories (Sunday in this case) serves as a baseline and doesn’t get a value. The others levels (Monday, Tuesday, etc.) each get their own indicator variable—so, their own column in the model matrix—which equals “1” on that day (i.e., “1” for the Monday column if the date of the observation is a Monday) and “0” on all other days.
Now let’s go back and look at the example of including temperature in the model as a nonlinear
function, starting with the simple example of using a second-degree polynomial. What would
the basis for that look like? We can find out by fitting the model and then looking at the
model matrix (the I() function lets us specify a transformation of a column from the
data when we set up the regression equation structure in glm):
mod_polynomial_temp <- glm(all ~ tmean + I(tmean ^ 2),
data = obs, family = "quasipoisson")
mod_polynomial_temp %>%
model.matrix() %>%
head()## (Intercept) tmean I(tmean^2)
## 1 1 3.913589 15.31618
## 2 1 5.547919 30.77941
## 3 1 4.385564 19.23317
## 4 1 5.431046 29.49627
## 5 1 6.867855 47.16743
## 6 1 9.232628 85.24142You can see that this has created two columns based on the temperature variable, one with it untransformed and one with it squared. The regression will estimate coefficients for each of these basis variables of temperature, and then that allows you to fit a model with a function of temperature, rather than solely temperature. Here are the coefficients from this model:
## # A tibble: 3 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 (Intercept) 5.31 0.00675 787. 0
## 2 tmean -0.0298 0.00126 -23.6 2.27e-119
## 3 I(tmean^2) 0.000667 0.0000538 12.4 5.70e- 35Therefore, it’s fit the following model to describe the association between temperature and mortality:
\[ log(E(Y)) = 5.3092 - 0.0298T + 0.0007T^2 \] If you want to estimate the relative risk of mortality at 15 degrees Celsius versus 10 degrees Celsius with this model (which is confounded by long-term and seasonal trends, so has some issues we’ll want to fix), you can take the following process. Take the two equations for the expected mortality when \(T\) is 15 and 10, respectively:
\[ log(E(Y|T=15)) = 5.3092 - 0.0298(15) + 0.0007(15^2) \\ log(E(Y|T=10)) = 5.3092 - 0.0298(10) + 0.0007(10^2) \] If you subtract the second from the first, you get:
\[ log(E(Y|T=15)) - log(E(Y|T=10)) = (5.3092 - 5.3092) - 0.0298(15 - 10) + 0.0007(15^2 - 10^2) \] which simplifies to (if the left part isn’t clear, review the rules for how you can manipulate logarithms):
\[ log(\frac{E(Y|T=15)}{E(Y|T=10)}) = - 0.0298(5) + 0.0007(125) = -0.0615 \] Exponentiate both sides, to get to the relative risk at 15 degrees versus 10 degrees (in other words, the ratio of expected mortality at 15 degrees to that at 10 degrees):
\[ \frac{E(Y|T=15)}{E(Y|T=10)} = e^{-0.0615} = 0.94 \] You can see that the basis variables are great in helping us explore how an independent variable might be related to the outcome in a non-linear way, but there’s a bit of a cost in terms of us needing to take some extra steps to interpret the results from that model. Also, note that there’s not a single coefficient that we can extract from the model as a summary of the relationship. Instead, we needed to pick a reference temperature (10 degrees in this example) and compare to that to get an estimated relative risk. We’ll see the same pattern as we move to using natural cubic splines to create the basis variables for temperature.
Now let’s move to a spline. The function the spline runs to transform the temperature
variable into the different basis variables is more complex than for the polynomial example,
but the result is similar: you get several columns to fit in the model for a variable, compared
to the single column you would include if you were only fitting a linear term. If you
take a look at the output of running the ns function on temperature in the data, you can
see that it creates several new columns (one for each degree of freedom), which will be the
basis variables in the regression:
## 1 2 3 4
## [1,] 0.1769619 -0.20432696 0.4777110 -0.2733841
## [2,] 0.2860253 -0.19686120 0.4602563 -0.2633951
## [3,] 0.2049283 -0.20410506 0.4771922 -0.2730872
## [4,] 0.2770456 -0.19804188 0.4630167 -0.2649748
## [5,] 0.4012496 -0.17595974 0.4113892 -0.2354295
## [6,] 0.6581858 -0.09844302 0.2476396 -0.1417190The output from ns also has some metadata, included in the attributes of the object, that
have some other information about the spline function, including where the knots were
placed and where the boundary knots (which are at the outer ranges of the data) are placed.
You can the str function to explore both the data and metadata stored in this object:
## 'ns' num [1:8279, 1:4] 0.177 0.286 0.205 0.277 0.401 ...
## - attr(*, "dimnames")=List of 2
## ..$ : NULL
## ..$ : chr [1:4] "1" "2" "3" "4"
## - attr(*, "degree")= int 3
## - attr(*, "knots")= num [1:3] 7.47 11.47 15.93
## - attr(*, "Boundary.knots")= num [1:2] -5.5 29.1
## - attr(*, "intercept")= logi FALSEThis is saying, for example, that the internal knots for this spline were put at the
25th, 50th, and 75th quantiles of the temperature data, where were 7.47 degrees, 11.47 degrees,
and 15.93 degrees. (The defaults for ns is to place knots evenly at percentiles, based
on the number of degrees of freedom you specify. You can change this by placing the knots
“by hand”, using the knots argument in the ns function.)
This spline object can be used not just for its basis values, but also to “predict” new basis values for a new set of temperature values. For example, you could figure out what the basis values from this spline would be for every degree of temperature between -6 and 29 using the following code:
temp_spline <- ns(obs$tmean, df = 4)
temp_spline_preds <- predict(temp_spline, newx = -5:30)
temp_spline_preds %>%
head()## 1 2 3 4
## [1,] 2.689545e-05 -0.01606406 0.03755734 -0.02149328
## [2,] 7.189726e-04 -0.04768237 0.11148013 -0.06379775
## [3,] 3.321933e-03 -0.07825364 0.18295494 -0.10470130
## [4,] 9.107577e-03 -0.10708098 0.25035250 -0.14327152
## [5,] 1.934771e-02 -0.13346753 0.31204355 -0.17857602
## [6,] 3.531412e-02 -0.15671641 0.36639881 -0.20968240This is handy, because it will help us visualize the relationship we fit in a regression model—we can start with these basis values for each degree in our temperature range, and then use the regression coefficients for each basis variable to estimate relative risk at that temperature compared to a reference temperature, exactly as we did in the equations for the polynomial function of temperature earlier, comparing 15 degrees C to the reference of 10 degrees.
All we need now are the regression coefficients for each of these temperature basis
variables. We can extract those from the model we fit earlier, where we included
ns(tmean, 4) as one of the model terms. Here, I’m using tidy to get the model
coefficients and then, because there are lots of them (from fitting a spline for
time with lots of degrees of freedom), I’m using the str_detect function from the
stringr package to pick out just those with “tmean” in the term column:
## # A tibble: 4 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 ns(tmean, 4)1 -0.0700 0.0135 -5.18 2.30e- 7
## 2 ns(tmean, 4)2 -0.0660 0.0126 -5.24 1.61e- 7
## 3 ns(tmean, 4)3 0.0110 0.0313 0.350 7.26e- 1
## 4 ns(tmean, 4)4 0.347 0.0177 19.6 2.02e-83You can add on pull to pull out just the estimate column as a vector, which will be
helpful when we want to multiple these coefficients by the basis values for each degree
of temperature across our temperature range:
temp_spline_ests <- mod_ctrl_nl_temp %>%
tidy() %>%
filter(str_detect(term, "tmean")) %>%
pull(estimate)
temp_spline_ests## [1] -0.06995454 -0.06596939 0.01095574 0.34659715Now, let’s put this together to see how relative risk of mortality changes as you move
across the temperature range! First, we can set up a dataframe that has a column with
each unit of temperature across our range—these are the temperatures where we want to
estimate relative risk—and then the estimated relative risk at that temperature. By
default, we’ll be comparing to the lowest temperature in the original data, but we’ll talk
in a minute about how to adjust to a different reference temperature. You can use
matrix multiplication (%*%) as a shorthand way to multiple each column of the spline
basis variables from temp_spline_preds by its estimated coefficient from the regression
model, saved in temp_spline_ests, and then add all of those values together (this is
the same idea as what we did in the equations earlier, for the polynomial basis). Then,
to get from log relative risk to relative risk, we’ll exponentiate that with exp. You
can see the first rows of the results below:
pred_temp_function <- tibble(
temp = -5:30,
temp_func = temp_spline_preds %*% temp_spline_ests,
rr = exp(temp_func)
)
pred_temp_function %>%
head()## # A tibble: 6 × 3
## temp temp_func[,1] rr[,1]
## <int> <dbl> <dbl>
## 1 -5 -0.00598 0.994
## 2 -4 -0.0178 0.982
## 3 -3 -0.0294 0.971
## 4 -2 -0.0405 0.960
## 5 -1 -0.0510 0.950
## 6 0 -0.0608 0.941This is now very easy to plot, with a reference line added at a relative risk of 1.0:
ggplot(pred_temp_function, aes(x = temp, y = rr)) +
geom_point() +
geom_line() +
labs(x = "Temperature",
y = "Relative Risk") +
geom_hline(yintercept = 1.0, color = "red", linetype = 2)
We might want to shift this, so we’re comparing the temperature at which mortality risk is lowest (sometimes called the minimum mortality temperature). This tends to be at milder temperatures, in the middle of our range, rather than at the minimum temperature in the range. To start, let’s see what temperature aligns with the lowest relative risk of mortality:
## Warning: Using one column matrices in `filter()` was deprecated in dplyr 1.1.0.
## ℹ Please use one dimensional logical vectors instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.## # A tibble: 1 × 3
## temp temp_func[,1] rr[,1]
## <int> <dbl> <dbl>
## 1 6 -0.0938 0.911We can therefore realign so that the relative risk equals 1.0 when the temperature is 7 degrees C, and all other relative risks are relative to a reference temperature of 7 degrees C:
pred_temp_function <- pred_temp_function %>%
mutate(temp_func_reset = temp_func - temp_func[temp == 7],
rr_reset = exp(temp_func_reset)
)
ggplot(pred_temp_function, aes(x = temp, y = rr_reset)) +
geom_point() +
geom_line() +
labs(x = "Temperature",
y = "Relative Risk") +
geom_hline(yintercept = 1.0, color = "red", linetype = 2)
This is a fairly cumbersome process, as you’ve seen with this example, and it would be a
pain if we had to do it every time we wanted to visualize and explore results from fitting
regressions that include basis variables from splines. Fortunately, there’s a nice R package
called dlnm (for “distributed lag nonlinear models”) that will help take care of a lot of
these “under the hood” steps for us. Even better, this package will let us move on to more
complex crossbasis functions, where we fit non-linear functions in two dimensions, and help
us visualize and interpret results from those models.
To start, make sure you have the dlnm package installed on your computer, and then load
it in your R session. This package has a function called crossbasis that lets you build
a crossbasis function to use in a regression model. We’ll talk more about these types
of functions later in this chapter; for right now, we’ll be a bit simpler and just use it
to create our spline function of temperature.
In the crossbasis function, you start by putting in the vector of the variable that you
want to expand into basis variables. In our case, this is temperature, which we have saved
as the tmean column in the obs dataset. You use the argvar to give some information
about the basis you want to use for that variable. This will both include the type of
basis function ("ns" for a natural cubic spline), and then also arguments you want to
pass to that basis function, like degrees of freedom (df) or knot locations (knots)
if you’re fitting a spline. The other arguments allow you to specify a function of lagged
time; we won’t use that yet, so you can just include lag = 0 and arglag = list(fun = "integer") to create a crossbasis where we only consider same-day effects in a simple way.
If you look at the output, you’ll see it’s very similar to the basis created by the
ns call earlier (in fact, the values in each column should be identical):
library(dlnm)
temp_basis <- crossbasis(obs$tmean, lag = 0,
argvar = list(fun = "ns", df = 4),
arglag = list(fun = "integer"))
temp_basis %>%
head()## v1.l1 v2.l1 v3.l1 v4.l1
## [1,] 0.1769619 -0.20432696 0.4777110 -0.2733841
## [2,] 0.2860253 -0.19686120 0.4602563 -0.2633951
## [3,] 0.2049283 -0.20410506 0.4771922 -0.2730872
## [4,] 0.2770456 -0.19804188 0.4630167 -0.2649748
## [5,] 0.4012496 -0.17595974 0.4113892 -0.2354295
## [6,] 0.6581858 -0.09844302 0.2476396 -0.1417190To estimate the regression coefficients, we’ll put this whole crossbasis in as one of
our terms in the glm regression equation:
dlnm_mod_1 <- glm(all ~ temp_basis + factor(dow, ordered = FALSE) +
ns(time, df = 158),
data = obs, family = "quasipoisson")As when we fit the spline earlier, you can see that this gives us a set of coefficients, one for each column in the matrix of crossbasis variables:
## # A tibble: 4 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 temp_basisv1.l1 -0.0700 0.0135 -5.18 2.30e- 7
## 2 temp_basisv2.l1 -0.0660 0.0126 -5.24 1.61e- 7
## 3 temp_basisv3.l1 0.0110 0.0313 0.350 7.26e- 1
## 4 temp_basisv4.l1 0.347 0.0177 19.6 2.02e-83However, there’s an advantage with using crossbasis, even though it’s looked pretty similar
to using ns up to now. That’s that there are some special functions that let us predict
and visualize the model results without having to do all the work we did before.
For example, there’s a function called crosspred that will give us a number of values,
including the estimated relative risk compared to a reference value. To use this, we
need to input the object name of our crossbasis object (temp_basis) and the name of our
regression model object (dlnm_mod_1). We also want to tell it which temperature we want
to use as our reference (cen = 7 to compare everything to 7 degrees C) and what interval
we want for predictions (by = 1 will give us an estimate for every degree temperature
along our range). The output is a list with a lot of elements, which you can get a view of
with str:
## List of 19
## $ predvar : num [1:35] -5 -4 -3 -2 -1 0 1 2 3 4 ...
## $ cen : num 7
## $ lag : num [1:2] 0 0
## $ bylag : num 1
## $ coefficients: Named num [1:4] -0.07 -0.066 0.011 0.347
## ..- attr(*, "names")= chr [1:4] "temp_basisv1.l1" "temp_basisv2.l1" "temp_basisv3.l1" "temp_basisv4.l1"
## $ vcov : num [1:4, 1:4] 1.83e-04 1.12e-04 3.85e-04 6.58e-05 1.12e-04 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : chr [1:4] "temp_basisv1.l1" "temp_basisv2.l1" "temp_basisv3.l1" "temp_basisv4.l1"
## .. ..$ : chr [1:4] "temp_basisv1.l1" "temp_basisv2.l1" "temp_basisv3.l1" "temp_basisv4.l1"
## $ matfit : num [1:35, 1] 0.0874 0.0756 0.064 0.0529 0.0424 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : chr [1:35] "-5" "-4" "-3" "-2" ...
## .. ..$ : chr [1, 1] "lag0"
## $ matse : num [1:35, 1] 0.01435 0.01254 0.01077 0.00907 0.00746 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : chr [1:35] "-5" "-4" "-3" "-2" ...
## .. ..$ : chr [1, 1] "lag0"
## $ allfit : Named num [1:35] 0.0874 0.0756 0.064 0.0529 0.0424 ...
## ..- attr(*, "names")= chr [1:35] "-5" "-4" "-3" "-2" ...
## $ allse : Named num [1:35] 0.01435 0.01254 0.01077 0.00907 0.00746 ...
## ..- attr(*, "names")= chr [1:35] "-5" "-4" "-3" "-2" ...
## $ matRRfit : num [1:35, 1] 1.09 1.08 1.07 1.05 1.04 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : chr [1:35] "-5" "-4" "-3" "-2" ...
## .. ..$ : chr [1, 1] "lag0"
## $ matRRlow : num [1:35, 1] 1.06 1.05 1.04 1.04 1.03 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : chr [1:35] "-5" "-4" "-3" "-2" ...
## .. ..$ : chr [1, 1] "lag0"
## $ matRRhigh : num [1:35, 1] 1.12 1.11 1.09 1.07 1.06 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : chr [1:35] "-5" "-4" "-3" "-2" ...
## .. ..$ : chr [1, 1] "lag0"
## $ allRRfit : Named num [1:35] 1.09 1.08 1.07 1.05 1.04 ...
## ..- attr(*, "names")= chr [1:35] "-5" "-4" "-3" "-2" ...
## $ allRRlow : Named num [1:35] 1.06 1.05 1.04 1.04 1.03 ...
## ..- attr(*, "names")= chr [1:35] "-5" "-4" "-3" "-2" ...
## $ allRRhigh : Named num [1:35] 1.12 1.11 1.09 1.07 1.06 ...
## ..- attr(*, "names")= chr [1:35] "-5" "-4" "-3" "-2" ...
## $ ci.level : num 0.95
## $ model.class : chr [1:2] "glm" "lm"
## $ model.link : chr "log"
## - attr(*, "class")= chr "crosspred"The one we’ll look at right now is allRRfit. You can extract it with (here I’m showing
how you can do it with piping and the pluck function to pull out an element of a list,
but you could do other approaches, too):
est_rr <- dlnm_mod_1 %>%
crosspred(basis = temp_basis, model = ., cen = 7, by = 1) %>%
pluck("allRRfit")
est_rr## -5 -4 -3 -2 -1 0 1 2
## 1.0913393 1.0785207 1.0661255 1.0543222 1.0432720 1.0331298 1.0240458 1.0161668
## 3 4 5 6 7 8 9 10
## 1.0096382 1.0046057 1.0012180 0.9996288 1.0000000 1.0024680 1.0064490 1.0106777
## 11 12 13 14 15 16 17 18
## 1.0138437 1.0147024 1.0135774 1.0122284 1.0124622 1.0160921 1.0245314 1.0378080
## 19 20 21 22 23 24 25 26
## 1.0557076 1.0780540 1.1046963 1.1354974 1.1703226 1.2090286 1.2514526 1.2974015
## 27 28 29
## 1.3466411 1.3988856 1.4537866To make it easier to work with, let’s put this in a dataframe. Note that the temperatures
are included as the names in the vector, so we can extract those with names:
dlnm_temp_function <- tibble(tmean = as.numeric(names(est_rr)),
rr = est_rr)
dlnm_temp_function %>%
head()## # A tibble: 6 × 2
## tmean rr
## <dbl> <dbl>
## 1 -5 1.09
## 2 -4 1.08
## 3 -3 1.07
## 4 -2 1.05
## 5 -1 1.04
## 6 0 1.03This has gotten us (much more quickly!) to estimates of the relative risk of mortality at
each temperature compared to a reference of 7 degrees C. We can plot this the same way we
did earlier, and you’ll notice that this plot is identical to the one we created based on the
regression with ns earlier:
ggplot(dlnm_temp_function, aes(x = tmean, y = rr)) +
geom_point() +
geom_line() +
labs(x = "Temperature", y = "Relative risk") +
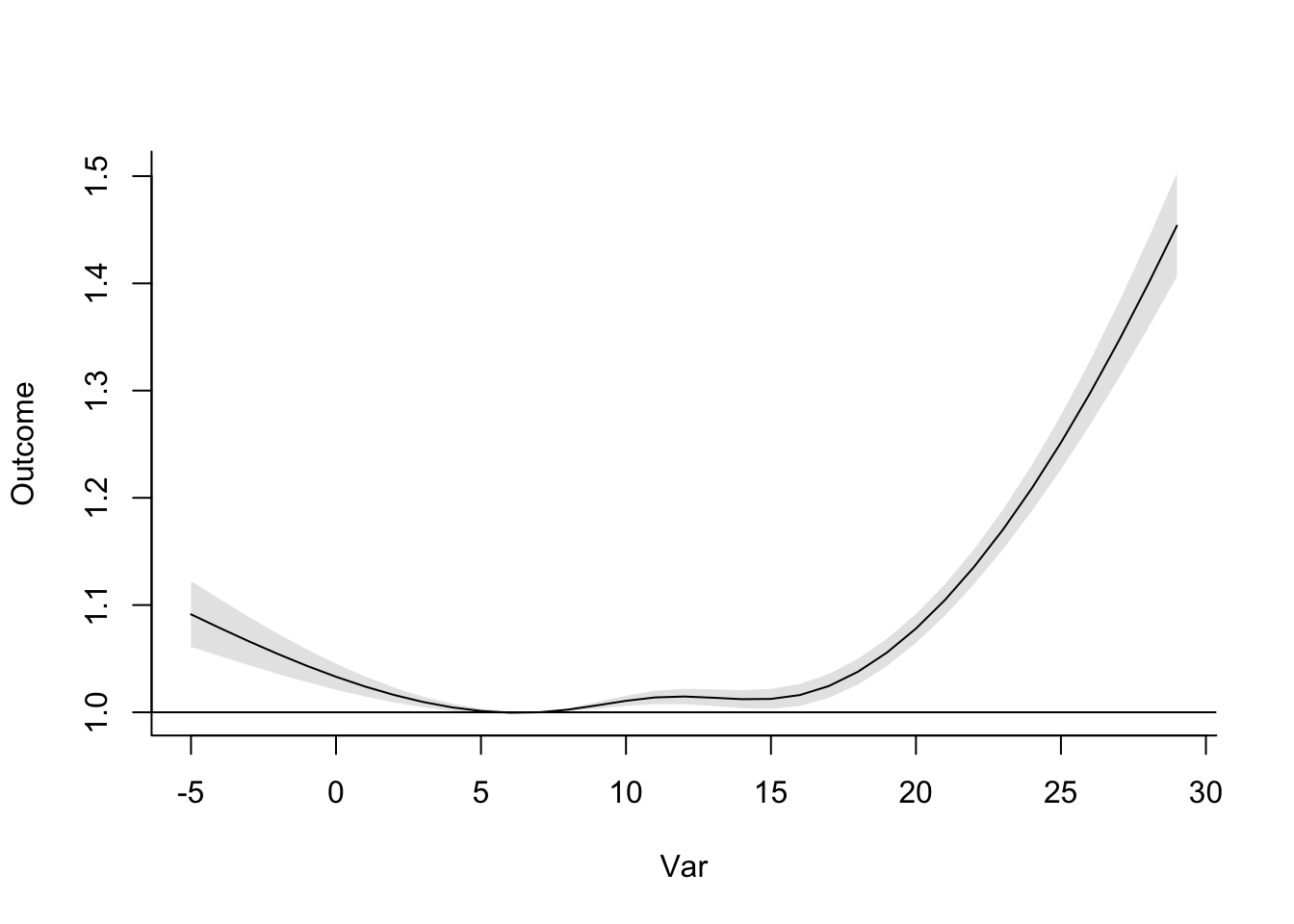
geom_hline(yintercept = 1.0, color = "red", linetype = 2)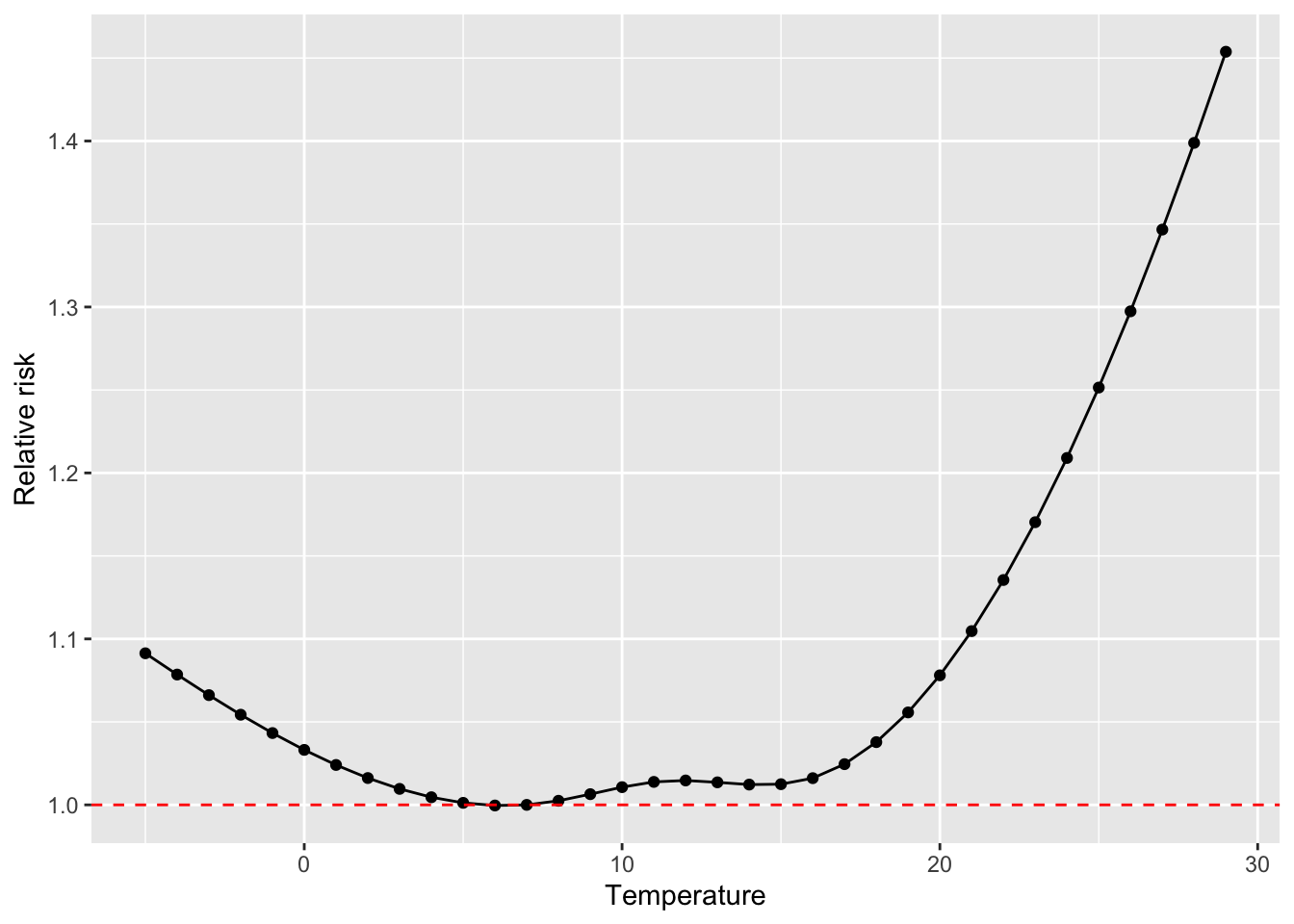
The dlnm package also includes some functions specifically for plotting. One downside
is that they’re in base R, rather than based on ggplot2, which makes them a bit
harder to customize. However, they’re a great way to get a first look at your results:
Don’t worry if all of this about basis functions is a lot! If this is the first time you’ve seen this, it will likely take a few passes to get comfortable with it—and while the idea of basis variables is fairly straightforward, it’s certainly not straightforward to figure out how to interpret the results of the model that you fit. It is worth the effort, though, as this is a very powerful tool when working with regression modeling in environmental epidemiology.
4.3 Distributed lags and cross-basis functions in GLMs
Next, let’s explore how we can add into our model something that lets us look at delayed effects and the potential for mortality displacement. So far, we have only considered how temperature affects mortality risk on the day of exposure—in other words, if it is very hot today, does risk of mortality go up substantially today? For many exposures, however, risk can persist after the day of exposure.
In some cases, this may be caused by a delay in detection of the outcome in the data we have. For example, extreme heat today could precipitate a respiratory or cardiac event that the person may not seek treatment for or result in an outcome like mortality until tomorrow, and so in the data the outcome would be recorded at a one-day delay from the exposure.
In other cases, the path from the exposure to the outcome may take several days. For example, cold temperatures are often found to be associated with respiratory outcomes a week or more after exposures (something you can look for in the example data!), and one potential pathway is that cold temperatures might promote the spread of respiratory infectious disease, like influenza and colds, both through making people stay inside in more crowded, less ventilated conditions and also through effects on humidity and other conditions that might influence the behavior of respiratory droplets, which are key players in spreading some respiratory diseases. Since there is an incubation time up to several days for these infectious diseases, we might expect a lagged association between temperature and respiratory outcomes under this scenario.
There is another lagged pattern that can be important to check for, as well—one that indicates mortality displacement. For many ambient environmental exposures, there are clear indications that associations with health outcomes are strongest among older adults or other populations with a disproportionately high percent of people who are frail before exposure. One question that comes up, then, is if, when an exposure is associated with excess deaths, these are deaths that are displaced in time by only a few days or weeks, rather than deaths that represent a larger time of life lost. This question—of whether deaths observed to be associated with an environmental exposure were displaced by only a small amount of time—can be explored by investigating whether an observed increase in mortality across a community during an exposure is then offset by a lower-than-expected rate of mortality in the following days and weeks.This phenomenon is sometimes also referred to as ‘harvesting’ or a ‘harvesting effect’.
All of these questions can be explored through a type of model called a distributed lag model. Conceptually, these models investigate how an exposure today is associated with risk of a health outcome not only today, but also in the following days. In time-series studies where we typically want to estimate potential short-term and/or acute effects, and because we are concerned about potential confounding by seasonal trends—and have incorporated control for these trends in our models—we often restrict these models to only look up to about a month following exposure. However, this can help in identifying delayed effects of an exposure days to weeks following the initial exposure, and can also help in determining the role of mortality displacement in accounting for some or all of the excess deaths that are associated with an exposure. While some environmental exposures of interest have mostly immediate effects (e.g., hot temperature), others, including many air pollutants, tend to have effects that are stretched over a longer period of one or more days from exposure. As a result, distributed lag models are used widely in environmental epidemiology studies of time series data, to ensure that important associations aren’t missed by limiting the model to focus on risk that are detectable on the same day as the exposure. They can also help us identify influential windows of exposure as well as help eliminate potential confounding by exposures occurring at proximal times to the window of interest. For example, today’s exposure may appear to have an effect on a health outcome even if in reality yesterday’s exposure is the influential one and we don’t control for it, because today’s and yesterday’s exposure to temperature or air pollution are likely to be very similar.
To fit a distributed lag model, you can start with a fairly straightforward extension of the regression models we’ve been fitting, especially if you are investigating an exposure that can be plausibly fit with a linear term (rather than a more complex non-linear basis function) in the regression model. Say you are starting, for example, from the following regression model:
\[ log(E(Y)) = \alpha + \beta X + \mathbf{\gamma^{'}W} + ns(time) \]
In this model, you are using a Poisson regression to investigate how risk of the health outcome (\(Y\)) changes for every unit increase in the exposure (\(X\)), assuming a linear relationship between the exposure and the log of the health outcome. The model can include control for confounders like day of week (\(\mathbf{W}\)) and long-term and seasonal time trends (\(ns(time)\)). This model should look familiar from some of the models we’ve fit earlier to the example temperature data.
To expand this model to explore associations of temperature at different lags, the simplest approach is to add a term for each lag—in other words, instead of only having a term for temperature on the same day as the outcome measurement, we’ll also include a term for temperature the previous day, and the day before that, and so on. For example, here’s what the model would look like if we included terms up to lag 2:
\[ log(E(Y)) = \alpha + \beta_{0} X_{0} + \beta_{1} X_{1} + \beta_{2} X_{2} + \mathbf{\gamma^{'}W} + ns(time) \] where \(X_0\) is temperature on the same day as the measured outcome \(Y\) (with an associated coefficient \(\beta_0\)), \(X_1\) is the temperature the day before (with an associated coefficient \(\beta_1\)), and \(X_2\) is the temperature two days before (with an associated coefficient \(\beta_2\)). The interpretation of each of these coefficients is similar—\(exp(\beta_2)\), for example, gives our estimate of the change in the relative risk of the outcome \(Y\) for every one-unit increase in the exposure two days prior.
It can become cumbersome to write out the separate terms for each lag day, so you’ll often see equations for distributed lag models written using a shorter approach with the \(\sum\) symbol. The \(\sum\) symbol expresses several terms that are added together and so is well-suited for shortening the expression of a distributed lag model. For example, the previous model equation could be rewritten as:
\[ log(E(Y)) = \alpha + \sum_{l=0}^2{\beta_lX_l} + \mathbf{\gamma^{'}W} + ns(time) \]
This version of a distributed lag model is nice because it is fairly simple—we’re taking the idea of fitting a linear term for an exposure, and then expanding it to include the exposure on earlier days by adding the same type of term for exposure measured at each lag. However, it does have some downsides. The main downside is that exposure tends to be very strongly correlated from one day to the next. Any time you put different terms in a regression model that are correlated, you create the risk of collinearity, and associated problems with fitting the model. The term collinearity refers to the idea that you have two or more columns in your model matrix that give identical (or, if you loosen the definition a bit, very similar) information. To fit coefficients for each term, the modeling algorithm is trying to identify weights to place on each column in the model matrix that result in a model that gives the best likelihood of the data you see. If two or more columns have (almost) identical information, then the algorithm struggles to determine how to distribute weight across these two columns. The implications are that you can end up with a lot of instability in model coefficients for the columns that are collinear, as well as very inflated estimates of the standard error. Long story short, it can cause problems in your regression model if you include independent variables that are very strongly correlated with each other, and so we usually try to avoid doing that.
There are alternative distributed lag models that can help avoid this instability that can arise from fitting a distributed lag by using a separate term for each lag. All of them share a common feature—they somehow fit a function of the lags instead of each separate lag, so that we end up adding fewer terms to the regression model (and, in turn, are somewhat constraining the pattern that the distributed lag effects follow). At the most extreme, you can use a function that reduces all the lag terms to a single term, which you can do by averaging the exposure across all lags. In other words, you could take the same-day temperature, yesterday’s temperature, and the temperature the day before that, and average those three temperatures to create the term you put in the model. The model equation in this case would look like:
\[ log(E(Y)) = \alpha + \beta_{\overline{0-2}} X_{\overline{0-2}} + \mathbf{\gamma^{'}W} + ns(time) \] where \(\overline{0-2}\) represents an average over lags 0 to 2, and so \(X_{\overline{0-2}}\) is the average of the exposure on lags 0, 1, and 2 compared to the day that \(Y\) is measured.
This approach avoids any issues with collinearity across exposure terms from different lags, because you’re only including a single term for exposure in the model. However, there is a downside—this model will provide you with a single estimate for the lagged effects, without allowing you to explore patterns across lags (for example, is the association mostly on the day of exposure, or are there some delayed effects on following days?). Instead, the main assumption is that the effect is constant across all days in the window of interest.
Another approach is more complex, but it allows you to explore patterns across lags.
Instead of reducing the lagged exposure to a single term in the model, you can reduce
it to a few terms that represent the basis for a smooth function. Often, a polynomial
or natural cubic spline function will be used for this. The details of setting up the
model become more complex, but fortunately there are software packages (like the dlnm
package in R) that help in managing this set-up, as we’ll explore in the exercise.
Packages like dlnm can help in extending the complexity of the distributed lag model
in other ways, too. So far, we have explored using a distributed lag model where we
are happy to model the exposure using a linear term. As we’ve seen in earlier exercises,
this isn’t ideal for temperature. Instead, temperature has a non-linear association
with mortality risk, with the lowest risk at mild temperatures and then increased risk
at both lower (colder) and higher (hotter) temperatures.
We can fit a GLM that incorporates the exposure using a non-linear shape while, at the
same time, including a non-linear function to describe how the association evolves
across lagged time following the exposure. The approach is to extend the idea of
using a basis function—instead of using a basis function in a single dimension, we’ll
use a cross of basis functions in two dimensions. One dimension is the level of exposure
(e.g., cold to hot temperatures), and the other is the timing between the exposure and
the outcome (e.g., same-day to lagged by many days). In terms of the mechanics of
building a model matrix to use to fit the regression model, everything follows directly
from the idea we explored earlier of using a function like a spline to create basis
variables in that model matrix for a term with a non-linear association with the
outcome variable. However, the mechanics do get quite cumbersome as so many terms are
included, and so again we will use the dlnm package to handle these mechanics as we
start to incorporate these cross-basis functions within a GLM.
Applied: Including a cross-basis function for exposure-lag-response in a GLM
For this exercise, you will continue to build up the model that you began in the examples in the previous chapter. The example uses the data provided with one of this chapter’s readings, Vicedo-Cabrera, Sera, and Gasparrini (2019).
- Start with the simple model describing how are daily mortality counts are associated with a linear function of temperature. Include control for day of week and long-term / seasonal trends. Add to this model a term that describes the lagged effects of temperature up to a week following exposure, using a separate model term for each lag. What patterns do you detect in the lagged effects of temperature?
- Start with the model from the first question, but change it to use a smooth function of lag to detect lagged effects, rather than fitting a seperate term for each lag. Extend the model to look at lagged effects up to a month following exposure. What patterns do you see in these lagged effects?
- Refine your model to fit for a non-linear, rather than linear, function of temperature, while also incorporating a function to describe lagged effects up to a month following exposure. Based on this model, what does the association between temperature and mortality look like at lag 0 days? How about at lag 21 days? What does the pattern of lagged effects look like when comparing the relative risk of mortality at a hot temperature (e.g., 28 degrees C) to a milder temperature (7 degrees C)? What about when comparing mortality at a cold temperature (e.g., -4 degrees C) to a milder temperature (7 degrees C)? If you use a constant term for the effect of exposure over a month as opposed to the smooth function you just used, how does the overall cumulative RR compare?
- Assume that we are interested in the potential effect of a 5-day heatwave occurring on lags 0 to 4? You can assess this as the effect of hot temperature (e.g., 28 degrees C) during these lags, while the temperature remains warm but more mild (e.g., 20 degrees C) the rest of the month, against constant 20 degrees C for the whole month. What is the effect under the ‘constant’ model? How about the smooth function lag model?
Applied exercise: Example code
- Start with the simple model describing how are daily mortality counts are associated with a linear function of temperature. Include control for day of week and long-term / seasonal trends. Add to this model a term that describes the lagged effects of temperature up to a week following exposure, using a separate model term for each lag. What patterns do you detect in the lagged effects of temperature?
We’ll start by looking at distributed lag associations by fitting a model with separate terms for each of the lags we want to fit. Here, we want to fit up to a week, so we’ll want eight terms in total: ones for the same day (\(X_0\)), the previous day (\(X_1\)), two days before (\(X_2\)), three days before (\(X_3\)), four days before (\(X_4\)), five days before (\(X_5\)), six days before (\(X_6\)), and seven days before (\(X_7\)).
Right now, our data have temperature lined up with the date of the recorded deaths:
## # A tibble: 6 × 3
## date all tmean
## <date> <dbl> <dbl>
## 1 1990-01-01 220 3.91
## 2 1990-01-02 257 5.55
## 3 1990-01-03 245 4.39
## 4 1990-01-04 226 5.43
## 5 1990-01-05 236 6.87
## 6 1990-01-06 235 9.23To add lagged temperature to the model, then, we’ll need to add some columns to our
data, so that the row for an observation includes not only the temperature on that
day, but also on each of the seven previous days. The lag function from the tidyverse
suite of packages can be used to create these columns:
obs <- obs %>%
mutate(tmean_1 = lag(tmean, n = 1),
tmean_2 = lag(tmean, n = 2),
tmean_3 = lag(tmean, n = 3),
tmean_4 = lag(tmean, n = 4),
tmean_5 = lag(tmean, n = 5),
tmean_6 = lag(tmean, n = 6),
tmean_7 = lag(tmean, n = 7))You can see below that each of these have taken tmean and then offset it by moving it down
by one or more rows (down one row for lag 1, two for lag 2, etc.). As a result, we now have
columns that give us today’s temperature, yesterday’s, and so on, all lined up with the
row with the observation for daily mortality:
## # A tibble: 6 × 10
## date all tmean tmean_1 tmean_2 tmean_3 tmean_4 tmean_5 tmean_6 tmean_7
## <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1990-01-01 220 3.91 NA NA NA NA NA NA NA
## 2 1990-01-02 257 5.55 3.91 NA NA NA NA NA NA
## 3 1990-01-03 245 4.39 5.55 3.91 NA NA NA NA NA
## 4 1990-01-04 226 5.43 4.39 5.55 3.91 NA NA NA NA
## 5 1990-01-05 236 6.87 5.43 4.39 5.55 3.91 NA NA NA
## 6 1990-01-06 235 9.23 6.87 5.43 4.39 5.55 3.91 NA NAYou’ll notice that this process has created some missing data right at the beginning of the dataset—we don’t know what the temperature was the day before Jan. 1, 1990, for example, since the study data starts on Jan. 1, 1990. With most time series, we’ll have plenty of days in the study period, so we’ll usually just allow these early dates to drop when the model is fit.
Now we’ll add all these terms to our regression model:
dist_lag_mod_1 <- glm(all ~ tmean + tmean_1 + tmean_2 + tmean_3 + tmean_4 +
tmean_5 + tmean_6 + tmean_7 +
factor(dow, ordered = FALSE) +
ns(time, df = 158),
data = obs, family = "quasipoisson")If you look at the output from the model, you can see that a regression coefficient has been fit for each of these distributed lag terms:
## # A tibble: 8 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 tmean 0.00749 0.000592 12.6 2.67e-36
## 2 tmean_1 -0.00255 0.000788 -3.23 1.25e- 3
## 3 tmean_2 -0.00152 0.000797 -1.91 5.68e- 2
## 4 tmean_3 -0.00243 0.000798 -3.05 2.31e- 3
## 5 tmean_4 -0.00106 0.000798 -1.32 1.86e- 1
## 6 tmean_5 -0.000515 0.000797 -0.645 5.19e- 1
## 7 tmean_6 -0.00107 0.000789 -1.36 1.73e- 1
## 8 tmean_7 -0.00209 0.000593 -3.52 4.30e- 4We can pull out all those estimates, calculate the 95% confidence intervals (do this before you take the exponential to get to the relative risk estimate, not after!), and then exponentiate all the terms to get estimates of relative risk of mortality per unit increase in temperature.
dist_lag_terms <- dist_lag_mod_1 %>%
tidy() %>%
filter(str_detect(term, "tmean")) %>%
mutate(lag = 0:7,
low_ci = estimate - 1.96 * std.error,
high_ci = estimate + 1.96 * std.error,
rr = exp(estimate),
low_rr = exp(low_ci),
high_rr = exp(high_ci)) %>%
select(term, lag, rr, low_rr, high_rr)
dist_lag_terms## # A tibble: 8 × 5
## term lag rr low_rr high_rr
## <chr> <int> <dbl> <dbl> <dbl>
## 1 tmean 0 1.01 1.01 1.01
## 2 tmean_1 1 0.997 0.996 0.999
## 3 tmean_2 2 0.998 0.997 1.00
## 4 tmean_3 3 0.998 0.996 0.999
## 5 tmean_4 4 0.999 0.997 1.00
## 6 tmean_5 5 0.999 0.998 1.00
## 7 tmean_6 6 0.999 0.997 1.00
## 8 tmean_7 7 0.998 0.997 0.999You can plot these estimates to explore how the association changes by lag (notice how
geom_pointrange is very helpful here!):
dist_lag_terms %>%
ggplot(aes(x = lag, y = rr)) +
geom_point() +
geom_pointrange(aes(ymin = low_rr, ymax = high_rr)) +
labs(x = "Lag days since exposure",
y = "Relative risk of mortality\nper degree increase in temperature") +
geom_hline(yintercept = 1, color = "red", linetype = 3)
You can also, as an alternative, use the dlnm package to fit this
model, using the crossbasis function
to set up the distributed lag basis to include in the regression, and then the crosspred
function to extract results after fitting the regression model and to plot results.
First, you’ll again use crossbasis to create the basis, as you did earlier when using this
package to fit a non-linear function of temperature. You will use the lag argument to say
the maximum lag you want to include—in this case, seven days (lag = 7). You can use
the argvar and arglag functions to specify the basis function for the exposure variable
and the distributed lag component. For right now, we’ll use a very basic linear function for
the exposure (temperature), using fun = "lin" within the argvar list of arguments.
To fit a separate coefficient for each lag, we can specify fun = "integer" in the
arglag list of arguments (later we’ll explore some other functions for the lag component).
library(dlnm)
dl_basis <- crossbasis(obs$tmean, lag = 7,
argvar = list(fun = "lin"),
arglag = list(fun = "integer"))If you take a peak at this crossbasis, you’ll notice that it’s doing something similar to
what we did when we added columns for lagged temperatures. The first column gives temperature
on the same day, the second on the previous day (and so is offset one down from the first
column), and so on. The crossbasis function deals with the missing early dates by setting
all column values to be missing on those days; in practice, this difference in set up
won’t create any difference in how the model is fit, as the glm function will by default
exclude any observations with any columns of missing data.
## v1.l1 v1.l2 v1.l3 v1.l4 v1.l5 v1.l6 v1.l7 v1.l8
## [1,] NA NA NA NA NA NA NA NA
## [2,] NA NA NA NA NA NA NA NA
## [3,] NA NA NA NA NA NA NA NA
## [4,] NA NA NA NA NA NA NA NA
## [5,] NA NA NA NA NA NA NA NA
## [6,] NA NA NA NA NA NA NA NA
## [7,] NA NA NA NA NA NA NA NA
## [8,] 7.958644 6.686216 9.232628 6.867855 5.431046 4.385564 5.547919 3.913589
## [9,] 7.268950 7.958644 6.686216 9.232628 6.867855 5.431046 4.385564 5.547919
## [10,] 9.510644 7.268950 7.958644 6.686216 9.232628 6.867855 5.431046 4.385564
## [11,] 10.424808 9.510644 7.268950 7.958644 6.686216 9.232628 6.867855 5.431046
## [12,] 7.368595 10.424808 9.510644 7.268950 7.958644 6.686216 9.232628 6.867855We can use this matrix of crossbasis variables now in our regression call:
dist_lag_mod_2 <- glm(all ~ dl_basis +
factor(dow, ordered = FALSE) +
ns(time, df = 158),
data = obs, family = "quasipoisson")Again, you can pull the regression coefficients directly out of the regression model object (and you can see how they’re identical to those from our first distributed lag model):
## # A tibble: 8 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 dl_basisv1.l1 0.00749 0.000592 12.6 2.67e-36
## 2 dl_basisv1.l2 -0.00255 0.000788 -3.23 1.25e- 3
## 3 dl_basisv1.l3 -0.00152 0.000797 -1.91 5.68e- 2
## 4 dl_basisv1.l4 -0.00243 0.000798 -3.05 2.31e- 3
## 5 dl_basisv1.l5 -0.00106 0.000798 -1.32 1.86e- 1
## 6 dl_basisv1.l6 -0.000515 0.000797 -0.645 5.19e- 1
## 7 dl_basisv1.l7 -0.00107 0.000789 -1.36 1.73e- 1
## 8 dl_basisv1.l8 -0.00209 0.000593 -3.52 4.30e- 4You can proceed from here to plot estimates by lag using ggplot, but you can also use
some of the special functions for plotting in dlnm. We can plot the “slice” of comparing
the relative risk at 1 degree C (var = 1) (this will give us the one-unit increase,
because by default the crossbasis set-up with 0 degrees as the baseline, so this is
one degree above that value). The crosspred function predicts based on two things: (1)
a crossbasis and (2) a regression model object that uses that crossbasis. Once you create
an object with crosspred, then the plot function has a
special method for plotting that object (to see the helpfile for this
plot method, type ?plot.crosspred in your R console).
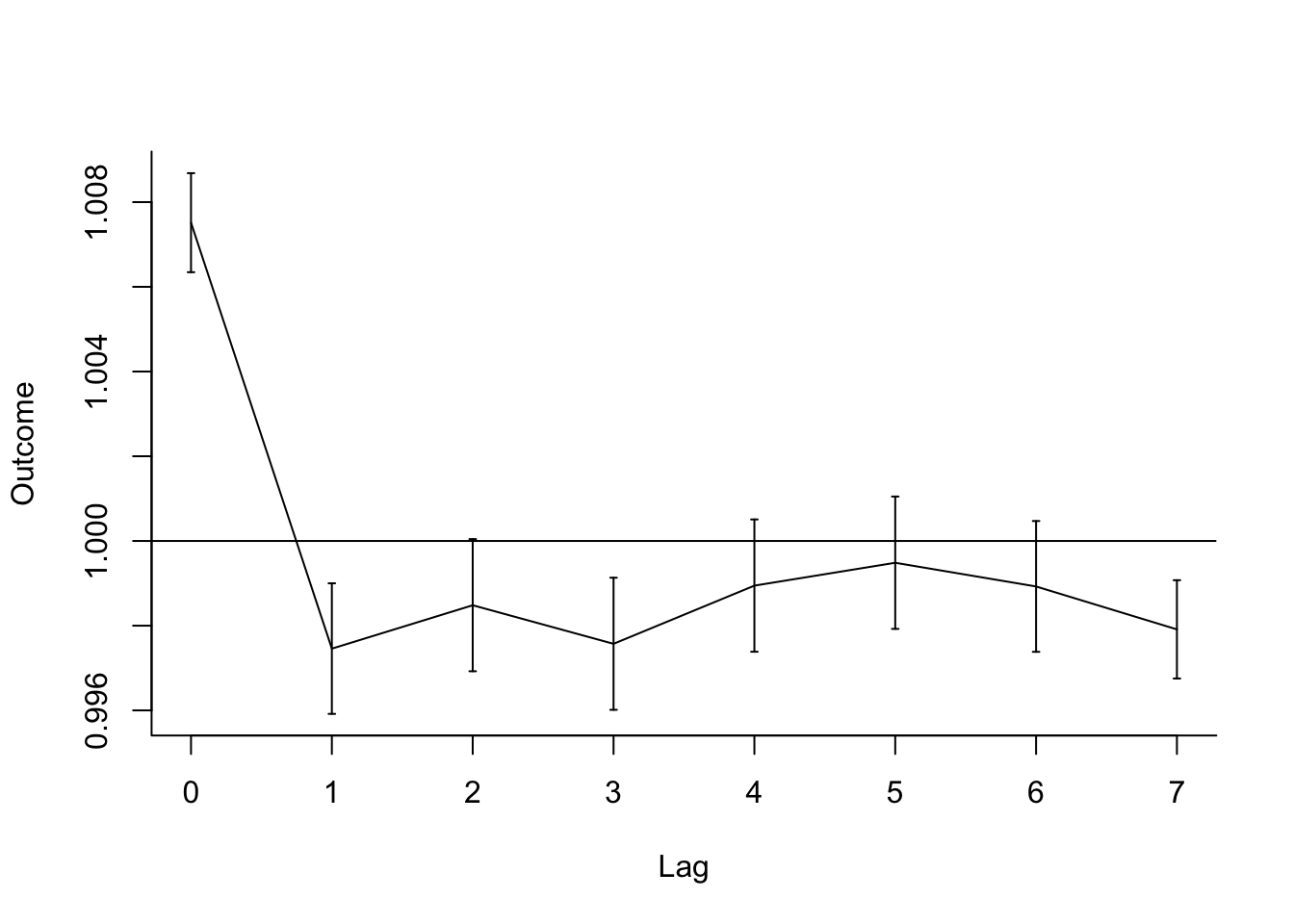
However, even though mechanically we can fit this model, we should think about whether it’s a good idea, or whether we should contrain the lag function some. If you look at the correlations between temperature at different lags, you’ll see they are very strongly correlated:
## tmean tmean_1 tmean_2 tmean_3 tmean_4 tmean_5 tmean_6
## tmean 1.0000000 0.9431416 0.8845767 0.8462589 0.8215974 0.8031790 0.7891306
## tmean_1 0.9431416 1.0000000 0.9431447 0.8846236 0.8463419 0.8216464 0.8032469
## tmean_2 0.8845767 0.9431447 1.0000000 0.9431403 0.8846198 0.8463094 0.8216348
## tmean_3 0.8462589 0.8846236 0.9431403 1.0000000 0.9431414 0.8846132 0.8463072
## tmean_4 0.8215974 0.8463419 0.8846198 0.9431414 1.0000000 0.9431482 0.8846132
## tmean_5 0.8031790 0.8216464 0.8463094 0.8846132 0.9431482 1.0000000 0.9431506
## tmean_6 0.7891306 0.8032469 0.8216348 0.8463072 0.8846132 0.9431506 1.0000000
## tmean_7 0.7781337 0.7892093 0.8032205 0.8216271 0.8463046 0.8846283 0.9431482
## tmean_7
## tmean 0.7781337
## tmean_1 0.7892093
## tmean_2 0.8032205
## tmean_3 0.8216271
## tmean_4 0.8463046
## tmean_5 0.8846283
## tmean_6 0.9431482
## tmean_7 1.0000000This means that we could have some issues with collinearity if we use this simpler distributed lag model, with a separate coefficient for each lag Next, we’ll explore a model that constrains the lagged effects to follow a smooth function, to help avoid this potential instability in the modeling.
- Start with the model from the first question, but change it to use a smooth function of lag to detect lagged effects, rather than fitting a separate term for each lag. Extend the model to look at lagged effects up to a month following exposure. What patterns do you see in these lagged effects?
As a reminder, we can stabilize our model of lagged effects a bit by fitting the
lagged effects to be constrained to follow a smooth function, instead of fitting a separate
term for each lag. The dlnm package makes this very easy to do.
When you use crossbasis to set up a crossbasis function, you can make a lot of choices
to customize that crossbasis. The crossbasis combines a basis function for incorporating
the exposure in the regression model (temperature in this case), as well as a basis function
for incorporating lagged effects of that exposure. The crossbasis functions gives you
several choices for each of these basis functions for the two dimensions of the
crossbasis. Here, we’ll look at using that flexibility for the lag dimension; in the next
part of the exercise, we’ll add some more complexity in the basis function for the
exposure, as well.
To customize the basis function for lagged effects, you can use the arglag parameter
in the crossbasis function. You send this parameter a list of other parameters, which
get sent to a general onebasis function that builds that basis function (this will
be convenient when we start working with the exposure basis, too—you’ll see that you
can use the same parameters in setting up each basis function).
To see the range of functions you can use for this crossbasis function, check the help
function for onebasis. When we fit a separate coefficient for each lag, we used the
“integer” function, which creates a set of basis variables with indicators for each
separate lag (this is really similar to the idea of basis variables for a categorical
variable, like day of the week). This is what we did in the first part of the exercise.
Now, we want to instead use a smooth function, with fewer degrees of freedom (i.e., fewer
columns created in the matrix of basis values). Two popular options for that function are
the “poly” function, which will fit a polynomial, or the “ns” function, which will fit
a natural cubic spline (just like we did earlier to create a non-linear function of
temperature). We’ll use “ns” in this example (fun = "ns" in the list of parameters for
arglag).
For some of these functions, you’ll need to specify additional parameters to clarify
how they should be built. For example, if you’re using a spline, you need to specify
how many degrees of freedom it should have with df. We’ll use 4 degrees of freedom,
but you can experiment with different values for this and see how it affects the shape
of the resulting function (i.e., the plot we create later). If you were fitting a
polynomial function,
you’d need to specify the degree of the polynomial; if you were fitting strata (i.e.,
constant values within sets of lags), you’d need to specify the breaks for dividing
those strata; if you were using a threshold function, you’d need to specify the threshold,
and so on. You can find more details on these options in the helpfile for onebasis;
in general, the onebasis function is using other underlying functions like ns and
poly to build these functions, so the choice of parameters will depend on the parameters
for those underlying functions.
Here is the final call for building this new crossbasis (note that we’re continuing to use a linear function of temperature, and at this point still only looking at lags up to a week; later in this question we’ll expand to look at longer lags):
dl_basis_2 <- crossbasis(obs$tmean, lag = 7,
argvar = list(fun = "lin"),
arglag = list(fun = "ns", df = 4))If you look at this crossbasis object, you’ll see that it’s created a matrix of basis variables, similar to the last part of the exercise. However, instead of having the same number of columns as the number of lags (8), we now have fewer columns. We have 4, reflecting the degrees of freedom we specified for the spline function of lag. Therefore, we’ve constrained the lag function a bit compared to the previous part of the exercise. Again, the values are all missing for the first seven days, since the data isn’t able to capture the lagged temperature for these days.
## v1.l1 v1.l2 v1.l3 v1.l4
## [1,] NA NA NA NA
## [2,] NA NA NA NA
## [3,] NA NA NA NA
## [4,] NA NA NA NA
## [5,] NA NA NA NA
## [6,] NA NA NA NA
## [7,] NA NA NA NA
## [8,] 10.53142 5.938107 17.26767 -2.9117904
## [9,] 11.46186 7.311815 17.99659 -2.0873124
## [10,] 10.91751 8.769682 19.69413 -3.2804334
## [11,] 10.94122 8.867758 22.33138 -2.7169313
## [12,] 13.00391 8.984807 22.20899 -0.3726342Again, once we build the crossbasis function, we can put it in the regression equation and
fit a regression model using glm:
dist_lag_mod_3 <- glm(all ~ dl_basis_2 +
factor(dow, ordered = FALSE) +
ns(time, df = 158),
data = obs, family = "quasipoisson")Again, you can plot the results to see the pattern of associations by lag. The plot
is just visualizing the results of predicting the model to certain values. By default,
it will predict at each lag; this makes the plot a little “jumpy” if you’re just looking
at lags for a week or so, so to make it smoother, you might want to ask crosspred to
predict to a finer resolution along the lag dimension (here, we’re using bylag = 0.2).
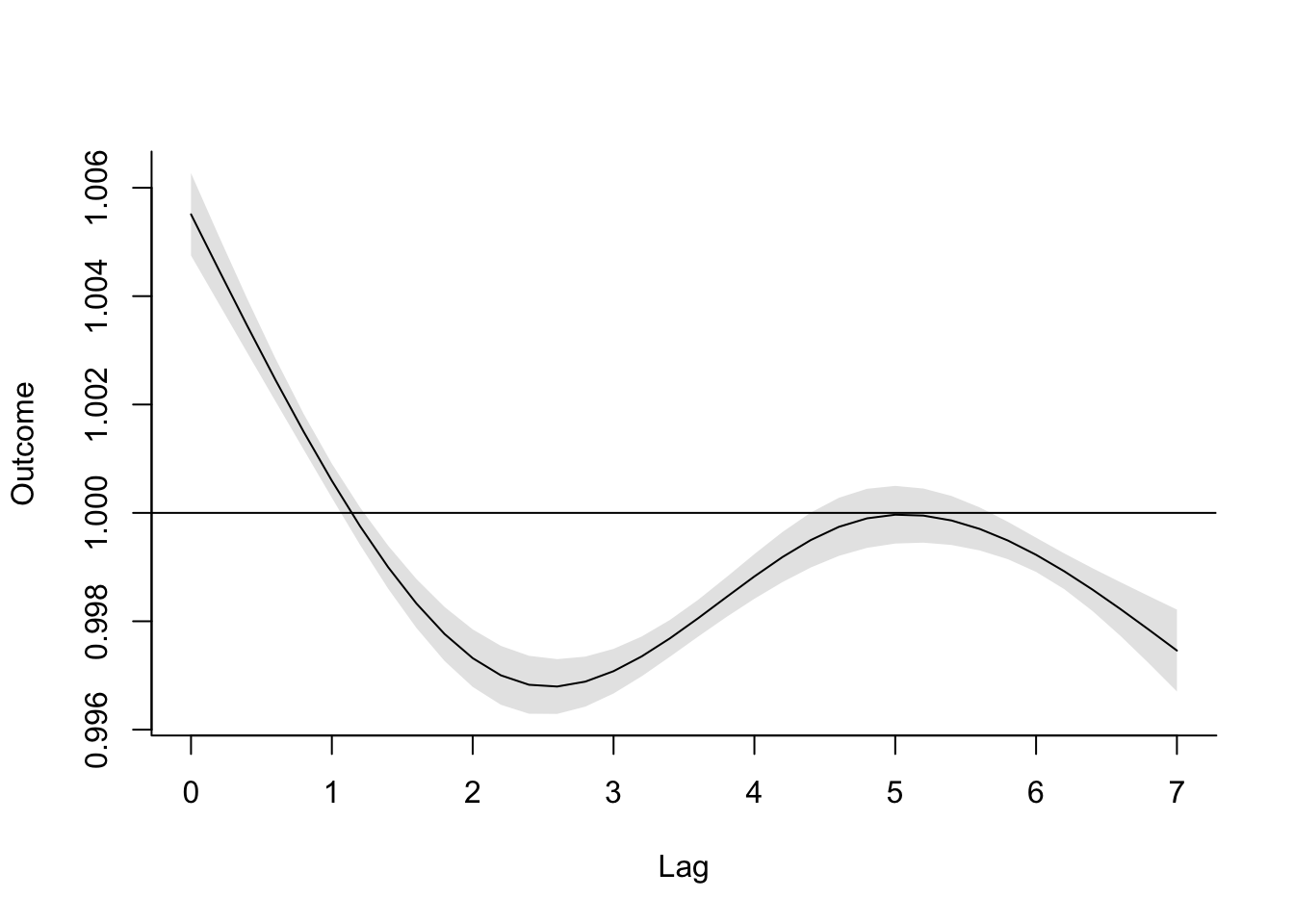
You can go back to the crossbasis call and try playing around with the degrees of freedom
for the spline, to see how that affects the shape of this function. Be sure, though, that
you don’t use more degrees of freedom than there are lags (i.e., more than 8).
Now let’s try to extend the model out to look at up to a month after exposure. To do this,
all you need to do is change the lag argument in crossbasis to the longest lag you
want to include. Since we’re adding more lags, you’ll likely also want to increase the
degrees of freedom you use for the basis function of lag; here, I’m using 6, but you can
explore other values as well (again, don’t use more than the number of lags, though).
From there, the process of fitting the model and plotting the results is identical.
dl_basis_3 <- crossbasis(obs$tmean, lag = 30,
argvar = list(fun = "lin"),
arglag = list(fun = "ns", df = 6))
dist_lag_mod_4 <- glm(all ~ dl_basis_3 +
factor(dow, ordered = FALSE) +
ns(time, df = 158),
data = obs, family = "quasipoisson")
crosspred(dl_basis_3, dist_lag_mod_4, at = 1) %>%
plot(ptype = "slices", var = 1)
- Refine your model to fit for a non-linear, rather than linear, function of temperature, while also incorporating a function to describe lagged effects up to a month following exposure. Based on this model, what does the association between temperature and mortality look like at lag 0 days? How about at lag 21 days? What does the pattern of lagged effects look like when comparing the relative risk of mortality at a hot temperature (e.g., 28 degrees C) to a milder temperature (7 degrees C)? What about when comparing mortality at a cold temperature (e.g., -4 degrees C) to a milder temperature (7 degrees C)? If you use a constant term for the effect of exposure over a month as opposed to the smooth function you just used, how does the overall cumulative RR compare?
To extend the model to include temperature using a non-linear function, we’ll go back
to the crossbasis call, but this time we’ll make some changes to the exposure variable
dimension. The basis function for the exposure is set using the argvar (“var” is
for “variable”) parameter. Again, this allows us to include a list of parameters that
will be passed to onebasis to build a basis function and set up basis variables for
this dimension of the crossbasis. We can use a spline for temperature by specifying
fun = "ns", as well as specify the degrees of freedom for that spline (here, I’ve used
4, but again, feel free to experiment):
dl_basis_4 <- crossbasis(obs$tmean, lag = 30,
argvar = list(fun = "ns", df = 4),
arglag = list(fun = "ns", df = 6))Try looking at the crossbasis from this function (you’ll need to look past the 30th row or so, since the earliest rows will all be missing since they’re in that range where they don’t have lag data available for the exposure). You can see that we now have a lot of columns: specifically, we have 4 (degrees of freedom for the temperature spline) times 6 (degrees of freedom for the lag spline) = 24 columns.
## v1.l1 v1.l2 v1.l3 v1.l4 v1.l5 v1.l6 v2.l1
## 1 NA NA NA NA NA NA NA
## 2 NA NA NA NA NA NA NA
## 3 NA NA NA NA NA NA NA
## 4 2.068939 3.299498 3.111270 1.738184 2.541810 -0.51512317 -0.5552531
## 5 1.955177 3.314862 3.125558 1.820183 2.690445 -0.40693744 -0.5967078
## 6 1.886111 3.299149 3.148516 1.893007 2.766242 -0.32385143 -0.6273517
## 7 1.882405 3.248469 3.180797 1.927784 2.804239 -0.08305771 -0.6419354
## 8 1.852973 3.165440 3.220817 1.900001 2.905860 0.08447527 -0.6588751
## 9 1.757370 3.058913 3.263914 1.795344 3.175517 0.03686863 -0.7106452
## 10 1.760596 2.944202 3.299498 1.779203 3.259667 -0.16712630 -0.7084665
## 11 1.797646 2.838520 3.314862 1.698607 3.497240 -0.17786583 -0.7118631
## v2.l2 v2.l3 v2.l4 v2.l5 v2.l6 v3.l1 v3.l2
## 1 NA NA NA NA NA NA NA
## 2 NA NA NA NA NA NA NA
## 3 NA NA NA NA NA NA NA
## 4 -0.7011824 -0.7707934 -0.4847858 -0.9916438 -0.0956588789 1.405249 1.838701
## 5 -0.6979016 -0.7603742 -0.4547662 -0.9667940 -0.0791413415 1.478133 1.830775
## 6 -0.7047091 -0.7492423 -0.4287099 -0.9503322 -0.0554076103 1.526744 1.841501
## 7 -0.7234011 -0.7371123 -0.4081381 -0.9450033 -0.0058689802 1.541114 1.873929
## 8 -0.7537142 -0.7241504 -0.4035141 -0.9205842 0.0358717107 1.565836 1.927170
## 9 -0.7930344 -0.7111578 -0.4381402 -0.7997450 -0.0007806944 1.643309 1.996194
## 10 -0.8364025 -0.7011824 -0.4373333 -0.7657041 -0.0621066847 1.644968 2.071685
## 11 -0.8780716 -0.6979016 -0.4735973 -0.6384769 -0.0958995727 1.631672 2.143093
## v3.l3 v3.l4 v3.l5 v3.l6 v4.l1 v4.l2 v4.l3
## 1 NA NA NA NA NA NA NA
## 2 NA NA NA NA NA NA NA
## 3 NA NA NA NA NA NA NA
## 4 1.955381 1.180876 2.353392 0.20605400 -0.8041945 -1.052250 -1.119024
## 5 1.942554 1.126503 2.294679 0.17194514 -0.8459049 -1.047714 -1.111683
## 6 1.926528 1.081359 2.257968 0.12135036 -0.8737239 -1.053852 -1.102512
## 7 1.906672 1.048474 2.249542 0.01133949 -0.8819473 -1.072411 -1.091149
## 8 1.883354 1.051489 2.198457 -0.07875894 -0.8960954 -1.102879 -1.077804
## 9 1.858659 1.116576 2.004017 -0.03652356 -0.9404317 -1.142380 -1.063672
## 10 1.838701 1.121782 1.943746 0.09297047 -0.9413808 -1.185582 -1.052250
## 11 1.830775 1.177720 1.763872 0.11448195 -0.9337721 -1.226447 -1.047714
## v4.l4 v4.l5 v4.l6
## 1 NA NA NA
## 2 NA NA NA
## 3 NA NA NA
## 4 -0.6757908 -1.346797 -0.117920408
## 5 -0.6446743 -1.313197 -0.098400617
## 6 -0.6188389 -1.292188 -0.069446282
## 7 -0.6000200 -1.287366 -0.006489356
## 8 -0.6017453 -1.258131 0.045072099
## 9 -0.6389933 -1.146857 0.020901671
## 10 -0.6419722 -1.112366 -0.053205061
## 11 -0.6739847 -1.009427 -0.065515636The dlnm package has done
the work of setting up this crossbasis function, as well as creating this matrix of
basis variables from our original simple column of temperature measurements. This
is getting to be a much more complex function than the simple linear/unconstrained lag
function that we started with. However, the underlying principles and mechanics are the
same, they’re just scaling up to allow some more complex “shapes” in our exposure-response
association.
We can add this new crossbasis function to the regression model, and then predict from the crossbasis and regression model to get a view of how temperature is (non-linearly) associated with mortality risk at different lags, comparing to a baseline temperature of 7 degrees C:
dist_lag_mod_5 <- glm(all ~ dl_basis_4 +
factor(dow, ordered = FALSE) +
ns(time, df = 158),
data = obs, family = "quasipoisson")
cp_dl <- crosspred(dl_basis_4, dist_lag_mod_5, cen = 7, bylag = 1)The object created by crosspred includes a lot of output (you can check out the
whole thing by running cp_dl to print it out). We can extract elements from this object
(for example, if we want to get effect estimates or estimates of confidence intervals).
We can also create a variety of plots from this object. The following plots all use the
plot method for crosspred objects, so you can access the helpfile with ?plot.crosspred.
First, we can look at “slices,” where we focus on just one lag value and look at the non-linear relationship between temperature and mortality risk at that lag only. For example, here are plots showing the relationship between temperature and mortality risk on the same day of exposure (lag 0) and 21 days after exposure (lag 21):

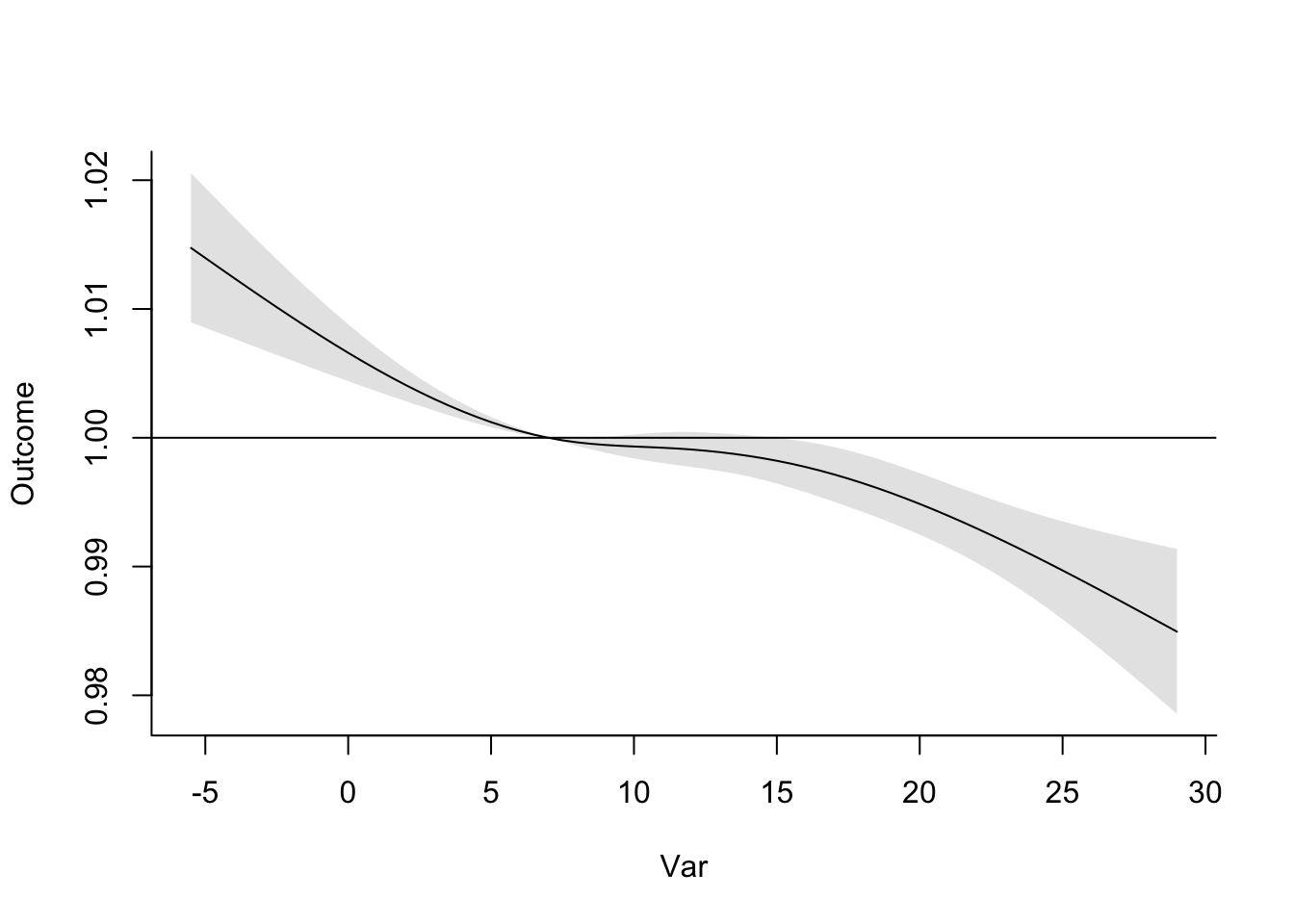
You can see that heat has a stronger relationship with mortality risk than cold at lag 0, while at a longer lag, there continues to be a positive association between cold temperature and mortality risk, but now the relationship with heat has shifted to be negative.
You can do the same idea of looking at a “slice” for a specific temperature, in this case
seeing how effects vary across lags when comparing that temperature to the baseline temperature
(7 degrees C, which we set when we ran crosspred). For example, here are “slices” for
28 degrees C and -4 degrees C:
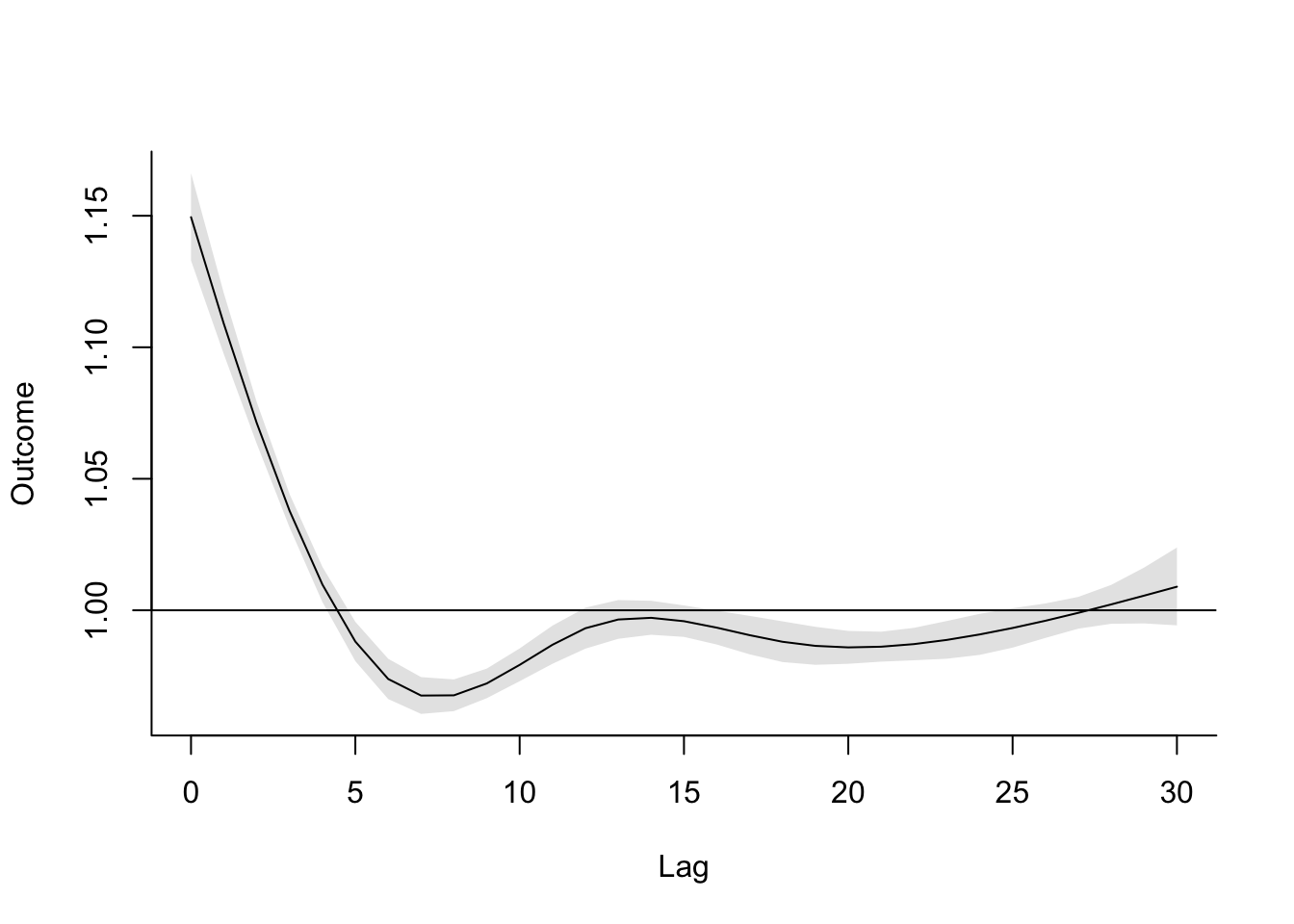
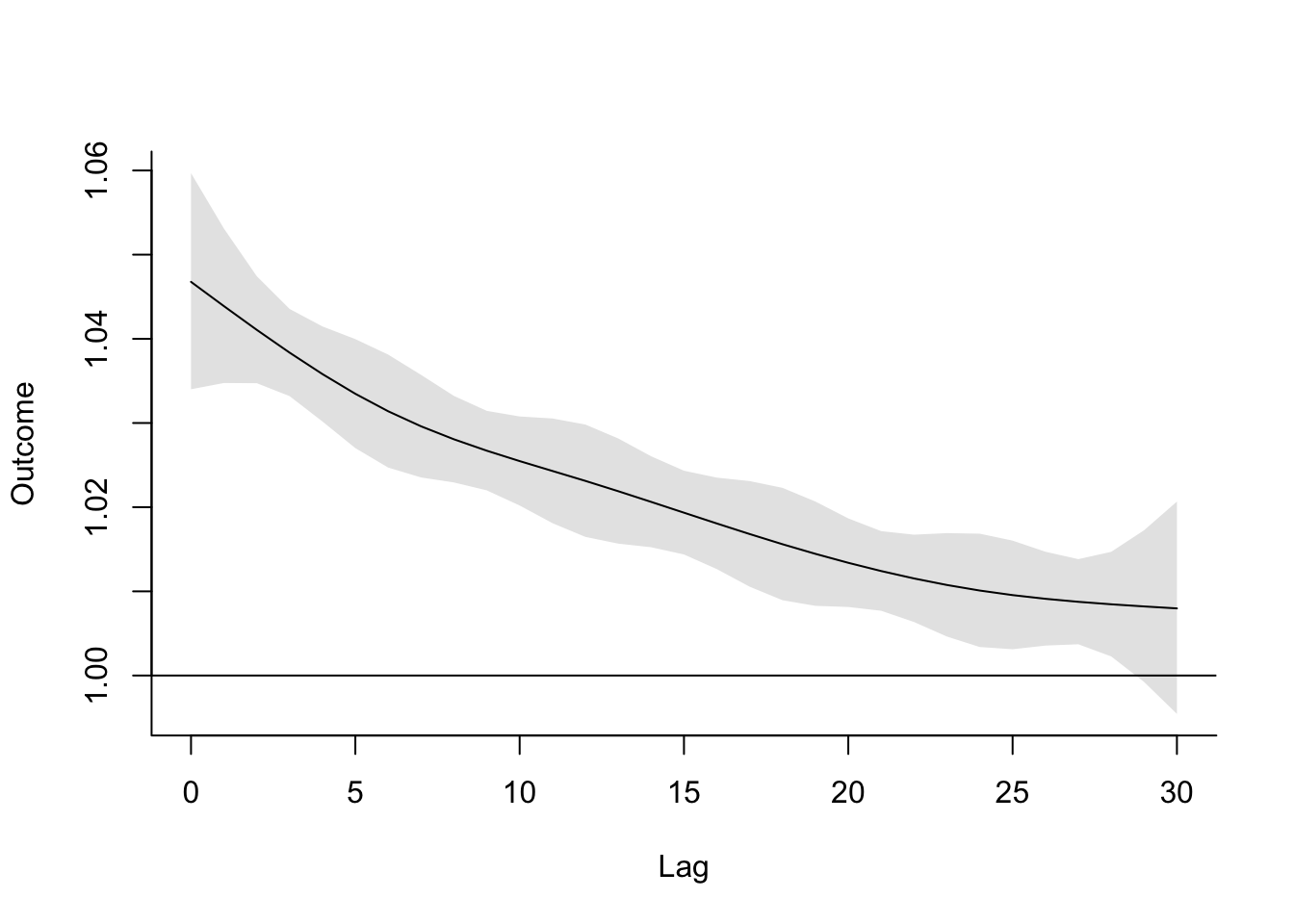 These plots again reinforce that heat’s association with mortality risk is more immediate,
while cold has an association that plays out over a much longer lag following exposure.
These plots again reinforce that heat’s association with mortality risk is more immediate,
while cold has an association that plays out over a much longer lag following exposure.
There are also some plots you can make from the crosspred object that help show the full,
three-dimensional association between the exposure, lag time, and risk of the outcome.
For example, the default plot created from the crosspred object is a three-dimensional
plot (the theta, phi, and lphi parameters shift the angle we view it from), while
the “contour” plot type shows us a contour plot of these results (in other words, showing
the exposure and lag variables in two dimensions of a two-dimensional plot then showing
relative risk using color for each combination). You can think of the ‘sliced’ plots from above as two-dimensional slices of the three-dimensional graph if we slice right at the selected lag or var value. Here is the code to create those plots:
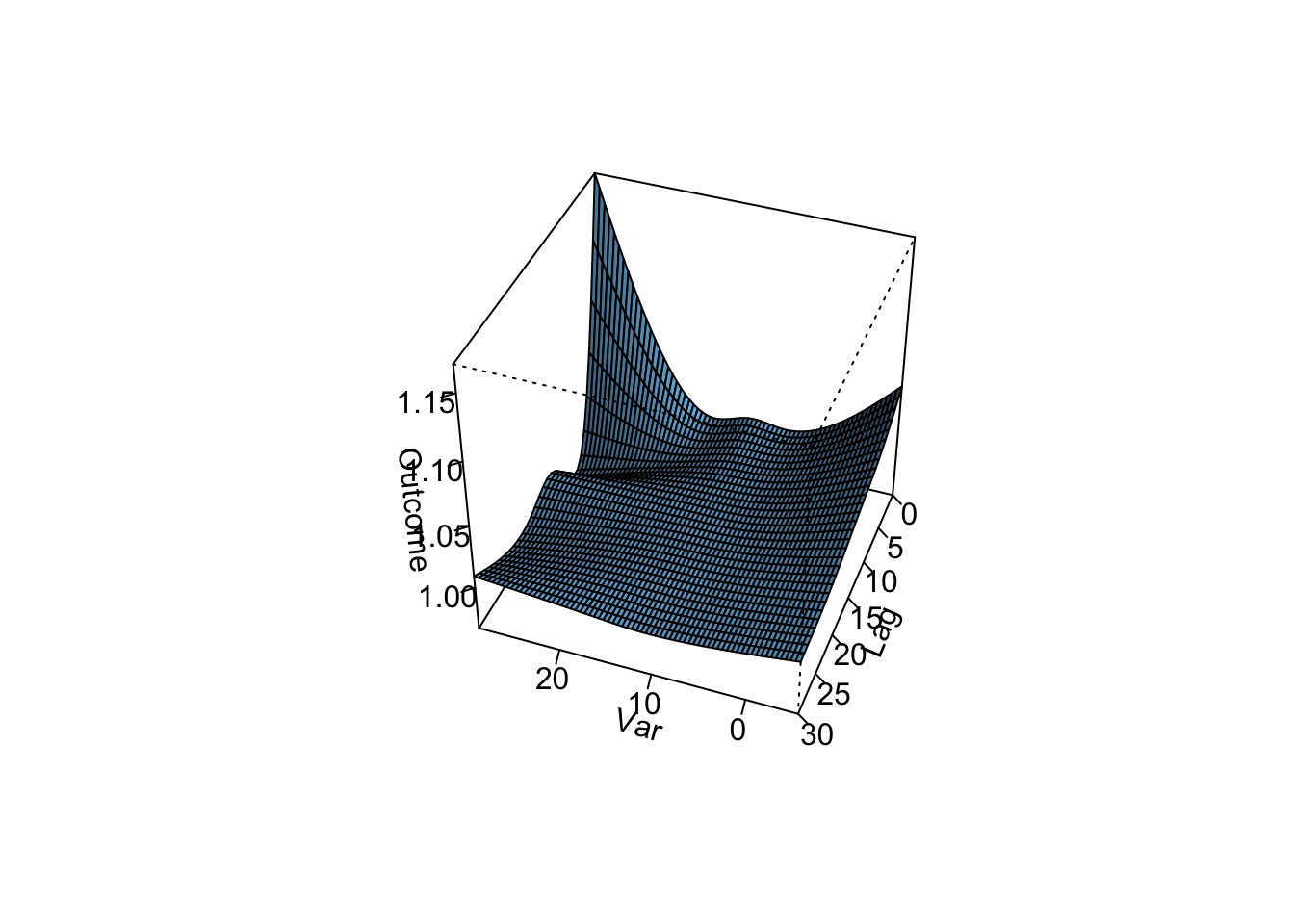
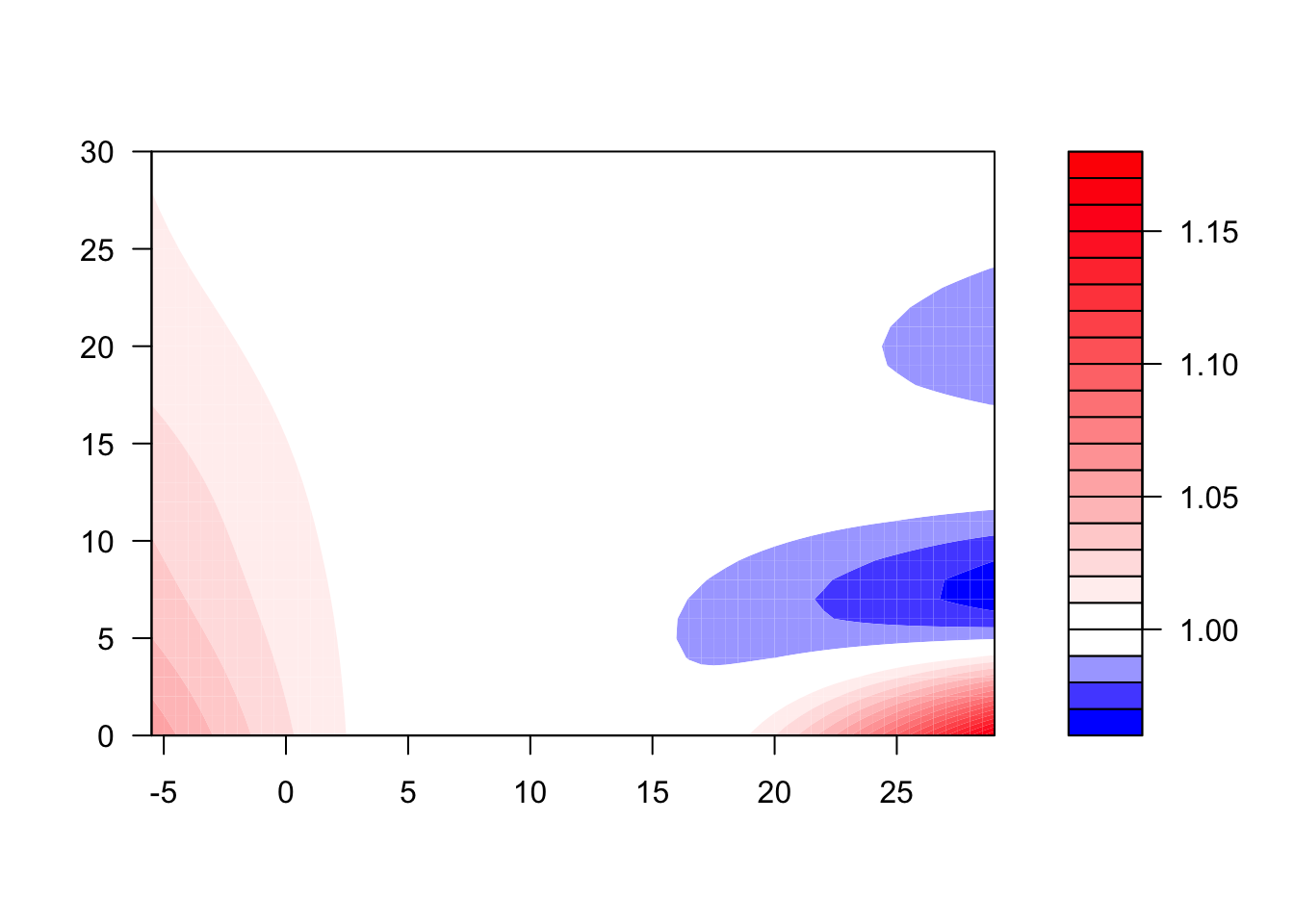
To see how a ‘constant’ lag-response model compares to the smooth function from this model we have to go back to the crossbasis and use the appropriate argument in the arglag parameter:
dl_basis_5 <- crossbasis(obs$tmean, lag = 30,
argvar = list(fun = "ns", df = 4),
arglag = list(fun = "strata", df = 1))The function strata in arglag essentially breaks up the lag window into strata equaling the degrees of freedom specified, and the lag-response is assumed to be constant for each day within each stratum. Here we specified df=1 so the lag-response is assumed to be constant for the entire lag window. In other words, the exposure in each day in the lag window is constrained to have the same effect. If we look at the crossbasis from this function you’ll see that we have far fewer columns. Remember that the total number of columns is determined by the total number of degrees of freedom, which is the product of the df’s in each of argvar and arglag so in this case 4.
## v1.l1 v2.l1 v3.l1 v4.l1
## 1 NA NA NA NA
## 2 NA NA NA NA
## 3 NA NA NA NA
## 4 14.69900 -4.438015 10.919532 -6.249020
## 5 15.03355 -4.382485 10.789984 -6.174883
## 6 15.21075 -4.347038 10.707109 -6.127455
## 7 15.33913 -4.332385 10.672850 -6.107850
## 8 15.51220 -4.298983 10.594759 -6.063160
## 9 15.89771 -4.127076 10.317738 -5.904626
## 10 15.96057 -4.094014 10.267995 -5.876159
## 11 16.37863 -3.880472 9.958228 -5.698886We can now run the same model as above replacing the crossbasis with the one we just created and
repeat the prediction to see how the temperature effect comparing to a baseline temperature
of 7 degrees C changes when we constrain the lag-response to be constant.
dist_lag_mod_6 <- glm(all ~ dl_basis_5 +
factor(dow, ordered = FALSE) +
ns(time, df = 158),
data = obs, family = "quasipoisson")
cp_dlconstant <- crosspred(dl_basis_5, dist_lag_mod_6, cen = 7, bylag = 1)If we look at the same plots and sliced plots as above we can see that this is a much simple model.
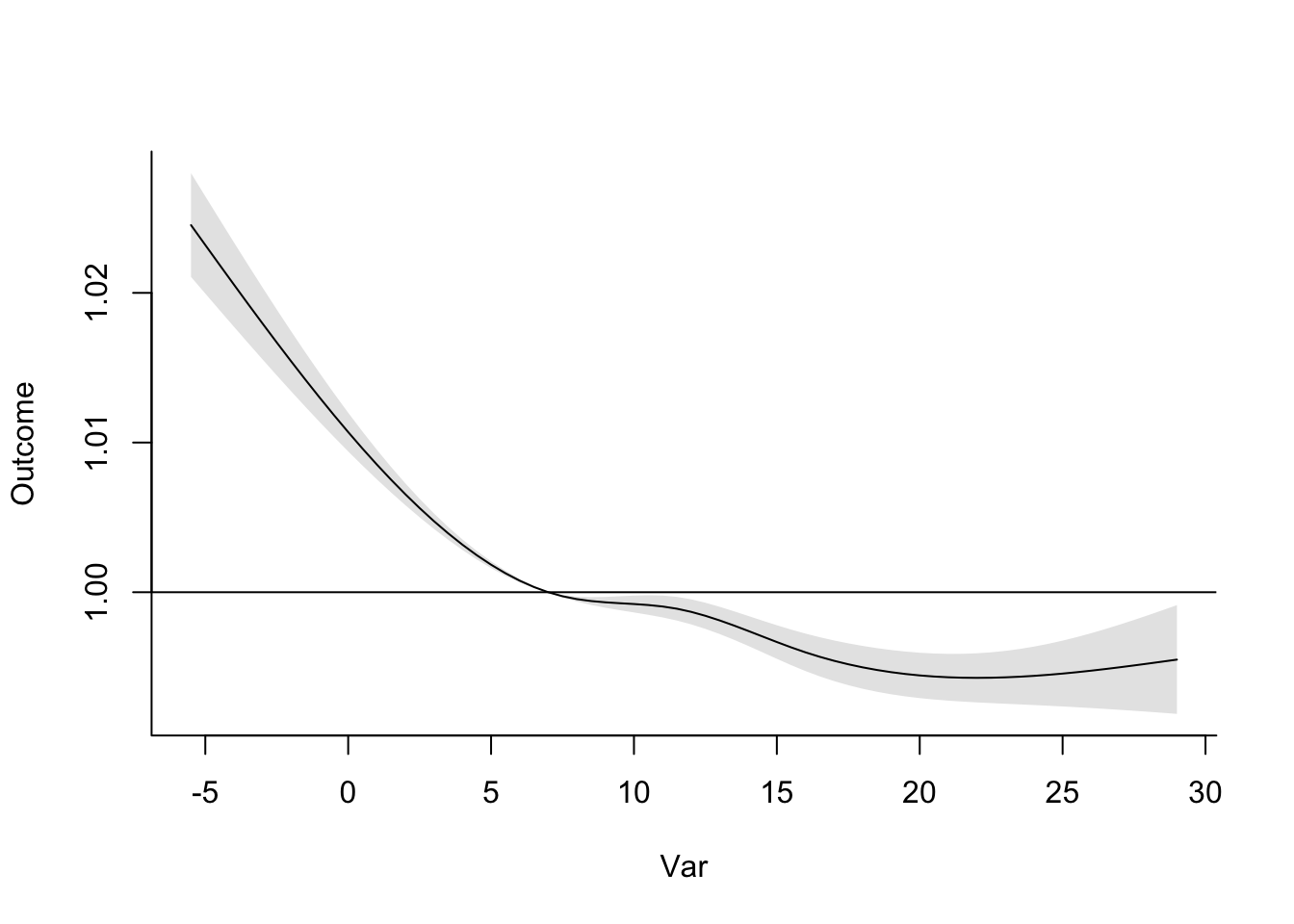
The two plots are identical (because we assume that the exposure-response is the same at all lags) with colder temperatures having a negative effect, while the warmer temperatures appear to be protective.


Here we see the constant lag-response more clearly, but at different effects depending on the set temperature. The hot temperature appears to be mildly protective (RR < 1.0), while the cold temperature is harmful (RR > 1.0).
The reduced complexity is evident in the 3-d plot (which looks “flat” on one of the dimensions) and the contour plot (which has large rectangular areas) as well.
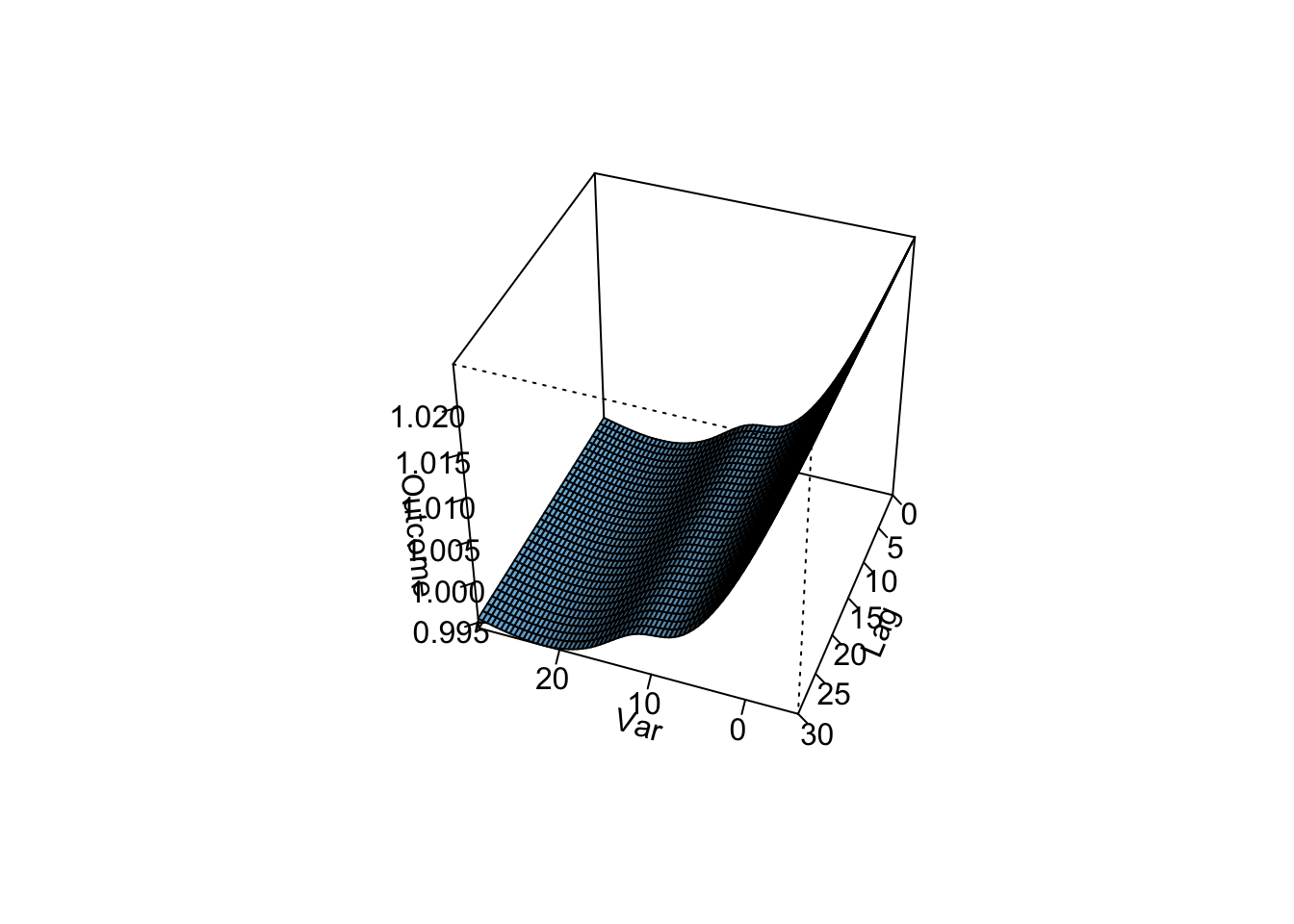

One other thing that we can do with the model output is we can estimate the cumulative risk
across lags, for example for a month of hot temperature (28 degrees C) compared to cooler temperature (7 degrees C). We do this by essentially accumulating the RRs from each lag-day as follows. The crosspred object has estimates of the coefficients for each lag day (in the
matfit element), and you
could add these up yourself, or you can extract a difference element (allfit) that has
already added these up for you to get a cumulative effect estimate. If you’d like to
calculate confidence intervals, you can get an estimate of the standard error for this
cumulative estimate with the allse element of the crosspred object. We can get all these
for a temperature of 28 degrees C; since we set the crosspred object to be centered at
7 degrees C, this will allow us to compare 28 to 7 degrees C:
## [1] -0.004774825 -0.004774825 -0.004774825 -0.004774825 -0.004774825
## [6] -0.004774825 -0.004774825 -0.004774825 -0.004774825 -0.004774825
## [11] -0.004774825 -0.004774825 -0.004774825 -0.004774825 -0.004774825
## [16] -0.004774825 -0.004774825 -0.004774825 -0.004774825 -0.004774825
## [21] -0.004774825 -0.004774825 -0.004774825 -0.004774825 -0.004774825
## [26] -0.004774825 -0.004774825 -0.004774825 -0.004774825 -0.004774825
## [31] -0.004774825### combined model parameter for the cumulative RR (this is the sum for all of the above parameters)
cp_dlconstant$allfit[cp_dlconstant$predvar==28]## 28
## -0.1480196### corresponding standard error for the cumulative RR parameter
cp_dlconstant$allse[cp_dlconstant$predvar==28]## 28
## 0.05128501If we exponentiate the model parameter we will get the cumulative RR estimate and likewise using the model parameter and standard error we can derive 95% Confidence Intervals (CIs) for the cumulative RR. For the central estimate:
\[ RR=exp(\beta)=exp(-0.148)=0.86 \] For the confidence interval:
\[ exp(\beta \pm 1.96*se) = exp(-0.148 \pm 1.96*0.05) = (0.78, 0.95) \]
The crosspred object, it turns out, stores this information as well (in the allRRfit, allRRlow, and allRRhigh elements), so we can extract these elements directly without doing the math:
## 28
## 0.8624142## 28
## 0.7799415## 28
## 0.9536078Does this look accurate? Do we expect a 14% decrease in mortality comparing a very hot month to a cool month?
Now let’s calculate the cumulative RR for temperature at 28 degrees for the smooth lag-response function model from before (i.e., pull those same elements from the model we fit before with a smoother lag-response function):
## 28
## 1.078548## 28
## 0.9768645## 28
## 1.190816Based on this model, we infer there’s about a 6% cumulative increase associated with a temperature of 28 degrees C compared to 7 degrees.
Does this look more accurate? Which of the two lag-response functions is more likely to be true?
- Assume that we are interested in the potential effect of a 5-day heatwave occurring on lags 0 to 4? You can assess this as the effect of hot temperature (e.g., 28 degrees C) during these lags, while the temperature remains warm but more mild (e.g., 20 degrees C) the rest of the month, against constant 20 degrees C for the whole month. What is the effect under the ‘constant’ model? How about the smooth function lag model?
Using the crosspred function we can compare any exposure history over a lag-window of interest to a reference value (or values varying over time in the same window). Realistically, a whole month of extremely high exposures is unlikely. Extreme phenomena (such as 28 degree mean daily temperature in London) are more likely to last a shorter period of time. Furthermore, the effect of an event like a heat wave (likely occurring in the summer) is probably better assessed with a referent value more akin to what the heat wave is replacing, i.e., a warm but more mild summer temperature rather than temperatures more likely to occur in other seasons. We saw above that the effect of hot temperatures tends to be more short term, so let’s assess the potential effect of a 5-day heatwave assessed on the last day of the heatwave. The rest of the days in the month are at 20 degrees C and we will use the same value as the referent value for the whole month. Realistically there will be variability in the temperatures during these days as well, but for the purposes of this exercise let’s keep it constant at 20 for simplicity. Let’s assess this effect using the constant lag-response model.
hw_constant <- crosspred(dl_basis_5, dist_lag_mod_6,
at = exphist(c(rep(20, 26), rep(28, 5)), times = 31, lag = 30) ,
cen = 20, bylag = 1)The exphist function allows us to designate distinct exposure values for the entire lag-window. The exposure values here appear in an oldest (lag30) to most recent (lag0) order. The times argument determines were the list of exposure begins in the lag window (here time = 31 or lag30 from 0-30). The effect estimate and corresponding CI can be extracted as above.
## 31
## 1.004005## 31
## 0.9891951## 31
## 1.019037Now, lets repeat this with the smooth function lag-response model:
hw_smooth<-crosspred(dl_basis_4, dist_lag_mod_5,
at = exphist(c(rep(20, 26), rep(28, 5)), times = 31, lag = 30) ,
cen = 20, bylag = 1)
hw_smooth$allRRfit## 31
## 1.402728## 31
## 1.356389## 31
## 1.450651We see that the constant lag-response model underestimates the RR and does not capture any potential effect of a heatwave, while the smooth term lag-response model indicates that there is a 40% increase in mortality for the last day of the heatwave. Note that this increase in mortality is not the only effect, as based on out model the heatwave started having an effect on the same day it started, i.e. we would expect all 5 heatwave days to have a temperature related increase in mortality compared to the days before the heat-wave. We can look at the increase in mortality for each day if we look at the individual effect estimates:
## lag0 lag1 lag2 lag3 lag4 lag5 lag6 lag7 lag8
## 31 0.1196662 0.09213574 0.06563143 0.04117951 0.01980617 0 0 0 0
## lag9 lag10 lag11 lag12 lag13 lag14 lag15 lag16 lag17 lag18 lag19 lag20 lag21
## 31 0 0 0 0 0 0 0 0 0 0 0 0 0
## lag22 lag23 lag24 lag25 lag26 lag27 lag28 lag29 lag30
## 31 0 0 0 0 0 0 0 0 0## lag0 lag1 lag2 lag3 lag4 lag5 lag6 lag7 lag8 lag9 lag10
## 31 1.127121 1.096514 1.067833 1.042039 1.020004 1 1 1 1 1 1
## lag11 lag12 lag13 lag14 lag15 lag16 lag17 lag18 lag19 lag20 lag21 lag22
## 31 1 1 1 1 1 1 1 1 1 1 1 1
## lag23 lag24 lag25 lag26 lag27 lag28 lag29 lag30
## 31 1 1 1 1 1 1 1 1The first day of the heatwave will have an effect corresponding to a lag0 effect:
\[ RR=exp(0.107)=1.11 \]
The second day of the heatwave will have an effect corresponding to a lag0 and lag1 effect:
\[ RR = exp(0.107 + 0.085) = 1.21 \]
(This quantity is also equal to the product of the lag-day specific RRs for lag0 and lag1:)
\[ 1.11 \times 1.09 = 1.21 \]
And so on, until we reach our last day of the heatwave with RR=1.39. There is a bidirectional relationship for this RR, as you can interpret this as the overall effect of the heatwave on mortality on the last day of the heatwave, or as the overall effect of temperature on the first day of the heatwave on mortality over the next 5 days.